Contents
- Number Systems
- Bitwise operators
- Binary arithmetic
- Floating point (IEEE-754)
- Floating point arithmetic
- Widening and Narrowing
Number Systems
For the most part, our numbers come in decimal, which is called base 10 since we have 10 digits per place. In terms of decimal, we have the digits 0 through 9 that marks each place. When we move to another place, we multiply by 10 (e.g., tens place, hundreds place, etc.).
Please note that for this lecture I will be separating long numbers with underscores _ just to make it easier to read. Some languages allow you to separate a number with underscores to make it easier to read. Unfortunately, C++ does not. You will get a syntax error if you try to make a literal with underscores in it.
You can think of numbers as their place and magnitude. For example, take the decimal number 3210. Essentially, this is the value: \(3\times 1000 + 2\times 100 + 1\times 10 + 0\times 1 = 3210\). To show the base, we can do it as powers of 10: \(3\times 10^3 + 2\times 10^2 + 1\times 10^1 + 0\times 10^0 = 3210\).
It’s fairly simple to see how base 10 gets put together, but we can do this same math for any base. We just need to know: (1) how many digits per place? and (2) what’s the base of the exponent? Well, #1 is easy. It’s just base. In base 10, we have 0, 1, 2, 3, 4, 5, 6, 7, 8, and 9, which is 10 total digits. In base 2, we have 0 and 1, which is 2 total digits. #2 comes from the name of the base. Base 16 has an exponent of 16. Base 2 has an exponent of 2. Base 8 has an exponent of 8.
If you look closely, you’ll notice that both questions are answered by the base. The base IS the number of digits per place AND the base IS the base of the exponent! So, we can see each digit place as \(\text{base}^{\text{place}-1}\). So, the ones digit of base 10 is \(10^{1-1}=10^0=1\).
Identifying Bases
Having different numbers in different bases can get confusing if you’re not careful. There are two ways to differentiate bases: (1) prefix and (2) suffix. We usually use prefixes when programming since having a subscript isn’t easy or feasible when coding.
| Base | Name | Prefix | Suffix | Examples |
|---|---|---|---|---|
| 2 | Binary | 0b | 2 | 0b1100 or 11002 |
| 8 | Octal | 0 or 0o | 8 | 013 or 138 |
| 10 | Decimal | None | 10 | 1234 or 123410 |
| 16 | Hexadecimal | 0x | 16 | 0x123f or 123f16 |
We can use the prefixes to differentiate the bases in C++. All of the integers below have the exact same value, just different bases. Some programming languages, such as Python, use 0o (zero followed by the letter o) instead of just a 0, but 0o does not work in C++…however it may in future releases. It does get confusing, but by adding a zero in front of a number in C++, it becomes base 8 (octal).
These are the most common bases, and C++ supports them. Not all bases are supported by programming languages. For example, if I wanted a number in base 4, I’d have to manually calculate its value in C++.
Notice that in hex, we use letters to express digits ≥ 10. In C++, and most languages, this can be expressed as a capital letter or a lowercase letter. C++ doesn’t care, so 0xFF is the same as 0xff or 0xfF.
Converting TO Decimal
Converting to decimal is the easier of the two because we can follow the formula above. If we know the base and the digits, we just multiply the digits by powers of that base. For example, let’s take a random base:
The binary system
Let’s take an example of a base two (binary) number: 10112. Just like base 10, this can be expanded to the following: \(1\times 2^3 + 0\times 2^2 + 1\times 2^1 + 1\times 2^0\). If we actually add those up, we can see that this number is \(8+2+1=11\). So, 10112 = 11.
Converting FROM Decimal
I call this the “price-is-right” method. What we’re doing is putting digits in place to represent the magnitude of the value we’re talking about. So, we need a starting point. Well, we look for the largest place in what we’re converting into to put a digit. We want to get as close as possible without going over–hence, the price is right method.
Example: Convert 171 to binary (base 2)
We look for the largest digit’s place, so we have the 1s, 2s, 4s, …, 64s, 128s, 256s. We see that 171 falls between 128 and 256, but since 256 is bigger than 171, we cannot use it. So, our first digit starts at the 128ths place. So, since we put a 1 here, we know that we’re representing 128 out of 171, so we need to express \(171-128=43\). Again, we look at the 32s place and 64s place. 43 falls between here, so we have to put a 1 in the 32s place. This represents 32 of 43, so we need to represent \(43-32=11\). Again, we need to represent 11. We have an 8s place and 16s place, so we need to add 8. Now, we need \(11-8=3\) more. We have a 2s place and a 4s place, so we need to put a 1 in the 2s place, which leaves us with 1. So, we put a 1 in the ones digit.
\(171_{10}=1010\_1011_2\). As you get more practice, you’ll start to see powers of two everywhere in computing.
Practice
Convert 181 into hexadecimal.
Sometimes it is easier to convert into one base and then into hex. Hex starts getting really large since \(16^3=4096\). So, let’s convert 181 into binary first. Then, we can take four digits at a time and convert into hexadecimal.
\(181=128+32+16+4+1\), so we need put 1s in the 128s place, 32s place, 16s place, 4s place, and 1s place: \(1011\_0101_2\). Now, we can take groups of four digits and convert into hex.
\(1011_2=11_{10}=\text{b}_{16}\).
\(0101_2=5_{10}=5_{16}\)
Therefore, 181 = 0xb5.
More Than 10 Digits (Hexadecimal)
Notice than in hexadecimal, we use letters a, b, c, d, e, and f to represent values greater than 9. The first 10 digits (0-9) are identical in shape and value. However, base 16 has 16 total digits. So, we need 6 more. This is where a (10), b (11), c (12), d (13), e (14), and f (15) come into play. Since we can only have ONE digit per place, we need some other way to represent numbers > 9.
| Digit | Decimal Value |
|---|---|
| 0 – 9 | 0 – 9 |
| a or A | 10 |
| b or B | 11 |
| c or C | 12 |
| d or D | 13 |
| e or E | 14 |
| f or F | 15 |
Hexadecimal Example
Let’s see how these digits work by a simple example: 0x2bcf. We know that this is base 16 by the prefix 0x. Therefore, these are powers of 16: \(2\times 16^3 + b\times 16^2 + c\times 16^1 + f\times 16^0\). We’re good until we get to the letters. So, we look at the table above and convert each letter into its equivalent decimal value: \(2\times 16^3 + 11\times 16^2 + 12\times 16^1 + 15\times 16^0\). Now, this is an equation we can solve. When we’re done, we’ll have the hexadecimal value in decimal. \(2\times 4096 + 11\times 256 + 12\times 16 + 15\times 1=8192+2816+192+15=11215\).
As you can see, hexadecimal gets out of hand fairly quickly as the exponent increases. This is why it is sometimes easier to convert to binary before converting to decimal.
Using printf with Different Bases
The printf() function contains several specifiers that will print in different bases. Per the standard, you can print base 8, base 10, and base 16 with printf as shown below. However, some printfs allow for printing binary.
int i = 100;
printf("%o\n", i);
printf("%d\n", i);
printf("%x\n", i);
The code above will print the value 100 in octal, decimal, and hexadecimal, which looks like the following:
144
100
64
Notice that prefixes are NOT automatically added. There are other flags you must specify if you want these. However, let’s take a look at this 144 is \(1\times 8^2 + 4\times 8^1 + 4\times 8^0=64+32+4=100\). For hex, \(6\times 16^1 + 4\times 16^0=96+4=100\).
Practice
Convert 0x32ab to decimal.
My preferred method for hexadecimal values over 3 digits is to first convert it to binary, then use binary to get the decimal value. So, let’s convert this to binary. Recall that each hex digit becomes 4 binary digits: \(3_{16}=0011_2\), \(2_{16}=0010_2\), \(\text{a}_{16}=(10_{10})=1010_{2}\), \(\text{b}_{16}=(11_{10})=1011_2\), which gives us \(0011\_0010\_1010\_1011_{2}\).
We always start at the ones place, which is the rightmost whole digit. In binary, as we move left the placement doubles since it is based on powers of 2.

All we need to do now is add those numbers with a 1 in the column to get the decimal value: \((2^{13}=8192)+(2^{12}=4096)+(2^9=512)+(2^7=128)+(2^5=32)+(2^3=8)+(2^1=2)+(2^0=1)\), reduced this becomes \(8192+4096+512+128+32+8+2+1=12971\). So, 0x32ab in decimal is 12971.
Fractions
Fractions are no different than what we’ve been doing. Notice that as we move left along the number, the exponent increases by 1, and when we move right, the exponent decreases by 1. Also notice that the one’s digit is a power of 0. So, what happens when we move right again? Well, the exponent still decreases by 1 to -1. Recall that a negative exponent is simply the reciprocal: \(2^{-1}=\frac{1}{2^1}=\frac{1}{2}\) and \(2^{-2}=\frac{1}{2^2}=\frac{1}{4}\).
Fractions in other bases can look weird, but there’s no magic to them. For example, 0xab.c can be decomposed as \(\text{a}\times 16^1 + \text{b}\times 16^0 + \text{c}\times 16^{-1}\). When we reduce this, we get \((10\times 16=160) + (11\times 1=11) + (12\times\frac{1}{16}=\frac{12}{16}=\frac{3}{4}=0.75)=171.75\).
Practice
I haven’t explicitly shown you binary fractions, but only the base changes from 16 above to 2. So, see if you can solve the following:
Convert 0b110.11 to decimal.
Again, we always start at home base, which is the one’s digit (exponent 0). So, let’s see how this boils down: \((1\times 2^2=1\times 4=4)+(1\times 2^1=1\times 2=2)+(0\times 2^0=0\times 1=0)+(1\times 2^{-1}=1\times \frac{1}{2}=0.5)+(1\times 2^{-2}=\frac{1}{2^2}=\frac{1}{4}=0.25)\). The whole portion becomes 6 (4+2+0) and the fractional portion becomes 0.75 (0.5+0.25). So, 0b110.11 = 6.75.
Many programming languages do not support fractional numbers in any base except base 10. It is important to know what language you’re using and whether or not it supports fractions of non-base-10 numbers. C++ currently doesn’t support hexadecimal fractions in their literals. However, a the newer 2017 C++ standard does. Again, it’s important to know the language you’re using! Just so you know, we use the 2011 C++ standard, so no hex fractions for us :(.
Computer Bases
I want you to be able to convert any base, which is why I haven’t really shown anything that relates base 2 to base 8 to base 16. However, I’d be remiss if I did not show how these are used in computers.
Octal
Base 8 is called octal, and it uses digits from 0-7. If you recall in binary 0b111 is the value 7 and 0b000 is the value 0. So, all digits in octal can fit in 3 binary digits. What makes this incredible is that we can just take three digits at a time and convert to the other base.
Convert 0o215 to binary.
0o215 is octal 215 (which is 141 in decimal, but you don’t need to know that for this problem). Recall that each octal digit is exactly 3 binary digits, so we take 2 and convert to binary, which is 0b010 using three digits, then 1 is 0b001, and 5 is 0b101. We then merge these together to form \(010\_001\_101\). 0b010_001_101 has a 1 in the 1s place, 4s place, 8s place, and 128s place, giving us \(128+8+4+1=141_{10}\).
Convert 0b11010011 into octal.
We have to break the binary number into groups of three digits. ALWAYS start from the ones digit. You’ll notice in the number above, we have 8 digits, which is not a multiple of 3, so we need to pad with extra zeros. 0b011_010_011. Notice we added a zero to the left. Just like in decimal, if we add zeroes to the left, it doesn’t change the magnitude: \(000075_{10}=75_{10}\).
Now we need to take each chunk of three and convert it into the equivalent octal: 0b011 = 3, 0b010=2, and 0b011 = 3, so 0b1101_0011 = 0o323.
Hexadecimal
When machines had a smaller amount of RAM or their registers were smaller, octal was used quite a bit. However, hexadecimal has started to rule in the hardware level since each hex digit represents exactly four binary digits.
Convert 0xabcd to binary.
Each hex digit is exactly four binary digits. So, all we have to do is convert a, b, c, and d to the binary equivalent using four digits. Recall that a = 10 = 0b1010, b = 11 = 0b1011, c = 12 = 0b1100, and d = 13 = 0b1101. So, all we need to do is put the digits together to form: \(1010\_1011\_1100\_1101_{2}\).
Convert 0b11010 into hex.
Just like what we did with octal, we need to make sure the number of digits we have is a multiple of four, since we will take four binary digits to form one hexadecimal digit. So, 0b1_1010 needs three zeroes to form an 8-digit number: 0b0001_1010. Then, we take each group of four and convert it to hex: \(0001_2=1_{16}\) and \(1010_2=10_{10}=\text{a}_{16}\). So, our hex number is 0x1a.
Converting to different bases is just a matter of figuring out what each place represents. The magnitude is the same. If we have 15 marbles, we want to have 15 marbles, regardless of the base. Quick what is 15 marbles in binary and hex? did you answer \(1111_{2}\) and \(\text{f}_{16}\)?
When converting to decimal, just lay out the numbers as increasing (or decreasing) powers of the base. When converting from decimal, use the price-is-right method. Don’t forget that sometimes it is easier to convert to one base before converting to another!
Lastly, we use octal (base 8) and hexadecimal (base 16) a lot in computing because base 8 is exactly 3 binary digits and base 16 is exactly 4 binary digits. Easy enough?
This will take some practice, but after you’ve done this enough, you’ll be able to convert to/from without thinking about it.
Video Lecture
Bitwise Operators
The smallest addressable memory unit in our modern computers (Intel/AMD, ARM, RISC-V, MIPS) is one byte. However, that’s 8-bits! So, what do we do to get to the bit level? We sort of have to fake it by “shifting” bits around. The term bitwise means “at the bit level”. So, a bitwise AND is an AND operator that operates on individual bits.
We have seen the logical comparison operators, such as && and ||, and how they work. Recall that a && b must have both a and b be true for the entire expression to be true. We are going to use the same logic, except now we do it for each bit in a number.
AND, OR, and NOT Bitwise Operators
Bitwise operators operate on individual binary digits. When you add two numbers, you line all of the digits places in columns. The same happens here. Each place (ones, twos, fours) of one number gets placed on another.
AND
The AND operation is a binary operator, meaning that it takes two operands (much like add, subtract, multiply, and divide). When we line all of the digits places, if there are two 1s, the result is a 1. Any other case, the output is a 0. The following table shows the inputs and outputs of the AND operation.
| Top operand | Bottom Operand | Output |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 0 |
| 1 | 0 | 0 |
| 1 | 1 | 1 |
As you can see here, when we stack the bits and align them in the correct digits order, the only way we can get an output of 1 is for both the top and bottom to be 1. Any other case will result in a 0 for that digits place.
In C++, the AND operator is specified by an ampersand (&), and is demonstrated as follows.
int a = 7;
int b = 6;
int c = a & b;
printf("%d", c);
To manually determine what C++ is going to print out above, let’s follow the checklist below:
- Convert all numbers to base 2 (binary).
- Align each digits place of one number over those of the other (digit places must be in the same column).
- Perform operation.
- Convert to whatever base is necessary.
Let’s take step 1 and convert 7 and 6 into binary. \(7_{10}=0111_{2}\) and \(6_{10}=0110_2\). Now, let’s line them up:
0111 <--- int a (7) & 0110 <--- int b (6) ------- 0110 <--- result (6)
Since we’re working in base 2, you can see that this is in fact bitwise. In the actual computer, there will be 32 digits since an integer is 32 bits.
The AND operator is commutative meaning that a&b is the same operation as b&a.
Inclusive OR
An inclusive OR is usually shortened to just OR whereas exclusive or is shortened to XOR (ex-OR). Just like the AND operation, this is performed bitwise after we align each digit place in the same column.
| Top operand | Bottom Operand | Output |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 1 |
Unlike an AND, as long as there is a 1 ANYWHERE in the column, the result for that digit place is a 1.
int a = 8;
int b = 6;
int c = 8 | 6;
printf("%d", c);
- Convert all numbers to base 2 (binary).
- Align each digits place of one number over those of the other (digit places must be in the same column).
- Perform operation.
- Convert to whatever base is necessary.
1000 <--- int a (8) | 0110 <--- int b (6) ------- 1110 <--- result (14)
Notice that in each column, as long as a 1 is present, the result for that place is also a 1.
Just like AND, inclusive OR is also commutative.
Exclusive OR (XOR)
The exclusive OR (XOR) operator is much like the OR operator except that EXACTLY one 1 must be present in each column. Let’s take a look at the truth table for XOR.
| Top operand | Bottom Operand | Output |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 0 |
- Convert all numbers to base 2 (binary).
- Align each digits place of one number over those of the other (digit places must be in the same column).
- Perform operation.
- Convert to whatever base is necessary.
int a = 7;
int b = 6;
int c = 7 ^ 6;
print("%d", c);
0111 <--- int a (7) ^ 0110 <--- int b (6) ------- 0001 <--- result (1)
As you can tell, if there are two zeros or two ones, the result is a zero, otherwise it is a one.
NOT (invert)
The NOT is also called the one’s-complement. All we do is look at all of the bits and flip all 0s to 1s and all 1s to 0s–essentially inverting all of the bits. This is a unary operator since it only operates on one operand.
char a = 7;
char b = ~a;
printf("%d", b);
~0000 0111 <--- char a (7) ---------- 1111 1000 <--- result (-8)
You might be asking yourself, “how does that become -8?” This will be explained below. However, the most important part of the NOT operator is that you need to pad it out to the data size. A char is 8-bits, so I am required to write out all 8 bits since EVERY digit is going to be flipped. If this was a short, I would need 16 digits, an int would need 32 digits, and a long would need 64 digits (except for some Windows machines).
Binary Signs (Negative/Positive)
A computer stores 0s and 1s usually for off and on, respectively. However, what does a computer have to do to store a negative number? There is no dash (-) or plus (+) in binary. Instead, a computer uses the most-significant bit as the sign bit. The most significant bit is the leftmost digit. This is why you must know the data size before determining if it is a negative number.
Let’s look back at what I produced using ~7, which was -8: 0b1111_1000. We look at the leftmost bit. If this bit is a 1, the number is negative, if it is a 0, the number is positive. The tricky part is that negative numbers are stored in two’s-complement format. Therefore, if we see that the sign bit is a 1, we can’t just get rid of it and figure out the magnitude of the operand.
Recall that one’s complement was simply flipping all bits (0s to 1s and 1s to 0s). The two’s complement is as simple. We perform the one’s complement then add 1. That’s it! So, let’s check our number: 0b1111_1000. We know it’s negative (if it is a char) because the 8th bit (digit place \(2^7\)) is a 1. Now, let’s flip all the bits and add 1 to see what its positive value is: ~0b1111_1000 = 0b0000_0111. Then, we add 1 = 0b0000_0111 + 1 = 0b0000_1000. This is the value 8. Since we know the value is negative, the final result is -8.
- Check most-significant bit (leftmost bit) of a signed data type.
- If the bit is 0, the value is positive. Read the value as written.
- If the bit is 1, the value is negative. Perform two’s complement to get the positive value. Attach a negative sign to it and you have your magnitude.
Bit Shifting
There are three ways we can shift bits: logical left shift, logical right shift, and arithmetic right shift. A shift essentially means to shift all of the bits together left or right. Each shifting operation takes a value and the number of places to shift. In C++, we use << for left shift and >> for right shift. C++ will distinguish between an arithmetic right shift and logical right shift based on the data type. Unsigned data types always use logical right shifts whereas signed data types always use arithmetic right shifts.
A shift just moves each digit right by a certain number of places or left by a certain number of places. Since we only have a certain number of digits, those bits that “fall off” the left or “fall off” the right are discarded.
int value_left = 71 << 1; // Take 71 and shift all bits left by 1 int value_right = 71 >> 1; // Take 71 and shift all bits right by 1
71 is the value 0b100_0111. However, for this, we have to know when we drop digits. 71 is an integer literal, meaning that it is a 32-bit, signed value. So, let’s expand this value: 0b0000_0000_0000_0000_0000_0000_0100_0111. Now, when we shift all digits left one place, we get: 0b0000_0000_0000_0000_0000_0000_1000_1110. Notice that when the one’s place moved to the two’s place, a zero replaced the ones place.
Left Shift
Let’s demonstrate an example here. Let’s take the value 9 (binary 1001) and shift it left 4 places to see what we get. First, we need to know our data size, so in C++, 9, would be an integer literal, which is 32-bits:
int result = 9 << 4;
printf("%d", result);

As you can see, all of the bits are shifted to the left by four places. The upper four digits (which were all zeroes) are discarded (represented by red in the figure above). The lower four places (1001) were moved and in their original spot, 0s were replaced (represented in green in the figure above).
Right Shift
Recall that there are two right shifts: arithmetic and logical. A logical right shift mimics the left shift except we move right instead of left. Values fall off the right and values on the left are replaced with zeroes. An arithmetic right shift does the exact same thing except instead of replacing zeroes on the left, it duplicates the sign bit.
Using Shifts for Quick Math
Right shifts shift all bits to the right by a provided number of places in binary. If we did this in decimal, we can see that we divide by 10 each place we move right: \(1000 >> 1=100=\frac{1000}{10}\). So, we can say a right shift is \(\frac{a}{10^x}\). Where a is the original value and x is the number of places we shift right.
With bitwise operators, we’re shifting bits, so it’s base 2. However, the formula is the same. \(0100_2>>1=0010_2=\frac{0100}{2}\). When we shift 4 >> 1, we get the value 2. So, the same formula holds: \(\frac{a}{2^x}\), where a is the original value and x is the number of places we shift right.
This should start cluing you into why we have two right shifts. Let’s take -4 as an 8-bit value: \(1111\_1100_2\). If we do a right shift, we’d expect -2 (\(\frac{-4}{2^1}\)). However, if we did a logical right shift, we would get \(1111\_1100_2>>1=0111\_1110_2=126_{10}\). How did we go from -4 to 126? That’s because a logical right shift destroys the sign bit.
An arithmetic right shift fixes this by replacing empty digits with the sign bit instead of 0s. So, given our example above, we would do: \(1111\_1100_2>>1=1111\_1110_2=-2_{10}\). That’s better! Notice a 1 replaces the sign bit instead of a 0. This yields us a -2, which is exactly what we wanted.
There is only one left shift, the logical left shift. Unlike right shift, a left shift multiplies the value by 2 for each shift. The formula is \(a << x=a\times 2^x\) where a is the original value and x is the number of places you left shift. Obviously, there is a limit since we do not have infinite digits.
Once again, an arithmetic right shift is used by C++ whenever the data type is signed and a logical right shift whenever the data type is unsigned. In C++, all integral data types are signed by default. You can use the unsigned keyword in C++ to remove the sign bit; however, you can no longer store negative numbers.
int a = 100; // implicitly signed integer signed int b = 100; // explicitly signed integer unsigned int a = 100; // explicitly unsigned integer
Unsigned Data Types
A char stores 8-bits, but one bit is used to store the sign. Therefore, only 7 bits are available to store the number’s magnitude. \(2^7=\pm~128\). Due to two’s complement, we actually have a range of -128 to 127: \(\text{~}1000\_0000_2+1=0111\_1111_2+1=1000\_0000_2=-128\) and \(0111\_1111_2=64+32+16+8+4+2+1=127\).
| Type | Size (bytes) | Signed Range | Unsigned Range |
|---|---|---|---|
| char | 1 | -128 to +127 | 0 to 255 |
| short | 2 | -32,768 to +32,767 | 0 to 65,535 |
| int | 4 | -2,147,483,648 to +2,147,483,647 | 0 to 4,294,967,295 |
| long | 8 (4 on Windows) | -BIG to +BIG | 0 to BIG |
Note about Windows: If you use Visual Studio or any of the Microsoft developer tools, a long data type is only 4 bytes. You must use long long. On Linux (your lab machines and Mac) a long is 8 bytes.
Notice that with unsigned, we lose the ability to store negative numbers, but we double the capacity. This is because we don’t waste a bit storing the sign. Recall that a char is 8 bits. If we take the sign bit off, then we have all 8 bits to store data: \(1111\_1111_2=128+64+32+16+8+4+2+1=255\). Finally, ONLY integral data types can be unsigned. There is NO such thing as an unsigned float or unsigned double.
This is why C++’s vector.size() member function returns an unsigned int. It’s not possible to have a negative size, but we can double its effective range by using an unsigned int.
Uses
So what’s this all about? Who cares about getting to the bit level? Usually hardware developers do. A register is a piece of memory in hardware. We can use a char to control 8 light-emitting diodes (LEDs). If I set a 1 in one the bits, it illuminates that LED. If we didn’t have bitwise operators, we’d need 8-bits for each LED!
Test
If we want to test a certain bit, we create what is called a mask. This is a group of bits that blocks all bits but the ones we’re looking at. We typically use AND to get certain bits. For example, say we want to see if bit 5 is a 1 or a 0. We would first shift bit 5 into the one’s place and AND it with the value 1. Here’s why:
char value = 121;
if (1 == ((value >> 5) & 1)) {
printf("Bit 5 is 1!\n");
}
else {
printf("Bit 5 is 0!\n");
}
Let’s take an 8 bit value 121 which is a signed char: \(121=0111\_1001_2\). From right to left, we start with bit 0 through 7. So, we want bit 5. If we shift 121 right 5 places, we get \(0000\_0011_2\). This is the value 3, so we didn’t isolate a single bit (which is either 1 or 0). However, if we AND this with 1, it will give us ONLY the 1s place, which is 1. This is called testing a bit.
0000 0011 <-- original value & 0000 0001 <-- mask --------- 0000 0001 <-- one's place is 1
Set
Setting a bit means to set a given digit’s place to the value 1. If it is already 1, it resets that 1 back to 1, essentially doing nothing. All other bits are left alone. Our goal is to shift a 1 over to the place we need it and OR it with the original value. Everything else is 0, recall that \( x | 0 = x\) meaning anything OR’d with 0 is itself, this allows us to ONLY change the bits we want. Say we want to set bit 5.
char value = 8; value |= (1 << 5); // set bit index 5 (two's place)
0000 1000 <--- value (8) | 0010 0000 <--- 1 << 5 (32) --------- 0010 1000 <--- result (40)
Notice that the every place was left untouched except the bit we wanted to set. When we make a bit the value 1, it is called setting the bit.
Clear
Clearing a bit means to set that digit’s place to 0 (the opposite of set). In this case, we need to do the same thing we did with set. However, recall that if we OR anything with 0, we get the original value, NOT zero. So, we need to use AND. Instead of putting a 1 in the digit’s place we want, we need to put a 0. Anything AND’d with 1 is itself, so that allows us to leave the rest of the digits untouched.
char value = 7; value = value & ~(1 << 2); // Clear bit index 2
In the code above, we clear bit 2. How? Well, when we do 1 << 2, everything is zero except the 4s place (\(2^2=4\)). However, recall that we want everything to be 1 except the place that we want to clear so that we can AND it and clear just that one place. (1 << 2) is the value 0b0000_0100, but the tilde (~) flips all 0s to 1s, which gives us 0b1111_1011.
0000 0111 <--- value (7) & 1111 1011 <--- ~(1 << 2) --------- 0000 0011 <--- result (3)
Notice that when we AND with 1, that place’s value didn’t change. We essentially moved a 0 under the place we wanted to clear and AND’d it. Anything AND’d with 0 is 0.
Example
Write a function called write_value() that takes an 8-bit value and puts those 8-bits in a 32-bit register between bits [21:14], do not change any other bits.
First, we have to understand what this question is asking. We have an 8 bit value, but the register we’re writing has multiple fields. We can write numerous examples, but the following is a diagram of what we’re looking at here.
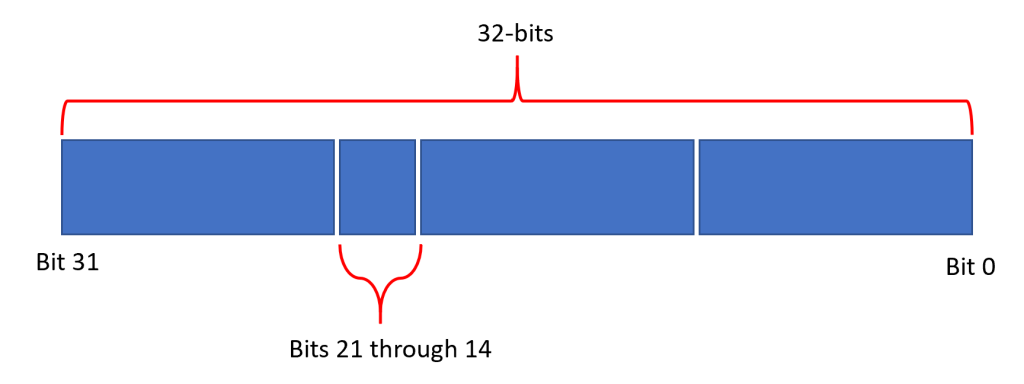
So, essentially, we’re given a value to write just in that little slice. Everything else must be left alone. So, let’s plan this out. (1) Let’s read the current value of the register so that we don’t touch the other bits. (2) Let’s clear out bits 21 through 14 so that we can use our set function above. (3) Let’s shift our 8-bit value left by 14 places to get it in the right place. (4) OR those values together to get the final result. (5) Write the entire 32-bits back into the register.
void write_value(unsigned char value, unsigned int *reg) {
unsigned int current_reg = *reg; // read current value
current_reg &= ~(0xff << 14); // 0xff is exactly 8 bits
current_reg |= static_cast<unsigned int>(value) << 14; // write value
*reg = current_reg;
}
0xff above is called a mask, here’s what we’re doing with it:
31 0 0000_0000_0000_0000_0000_0000_1111_1111 <-- 0xff 0000_0000_0011_1111_1100_0000_0000_0000 <-- 0xff << 14 Bit 21 -----^ ^---- Bit 14
Then we invert it and run the AND operation to clear ALL of those 8 bits out. The reason is because we don’t know what’s in there. If we OR a 0 there and the original value is 1, the new value is also 1, NOT 0!
So, why the static_cast? Recall that the value is only an 8-bit value. If we shift an 8-bit value left by 14 places, we discard anything that falls off of bit index 7. So, if we static cast this into an integer, we now have 32-bits to play with. When we left shift, those digits won’t fall off the left. Be VERY careful about your data types!
Ok fine, but how did you come up with 0xff? Well, we need to inclusively count bits 21 through 14 (21, 20, 19, 18, 17, 16, 15, 14), that’s 8 bits. Recall that each hex digit is exactly 4 bits. So, \(\text{f}_{16}=1111_2\). So, we can make an 8-bit mask by putting 0xff together.
Video
Binary Arithmetic
Essentially, we’re going to look at what addition, subtraction, multiplication, and division actually are and how we can do it in base 2. If we follow what we’re doing in base 10, we can simply “convert” our thinking to base 2.
Addition
When we add two numbers together, we’re combining two “blocks” of values together. This is no different in base 2. The only issue comes from when we carry a value out of a digit’s place that can’t hold it. For example 9 + 7 is 6 carry the 1 into the 10s place for the final value 16. With base 2, we can easily overflow the next digit (two’s place) if we have more than two values being added together.
Let’s take just one place and see what we get:
| Top Operand | Bottom Operand | Carry In | Sum | Carry Out |
|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 1 | 1 | 0 |
| 0 | 1 | 0 | 1 | 0 |
| 0 | 1 | 1 | 0 | 1 |
| 1 | 0 | 0 | 1 | 0 |
| 1 | 0 | 1 | 0 | 1 |
| 1 | 1 | 0 | 0 | 1 |
| 1 | 1 | 1 | 1 | 1 |
In the table above, we can see that \(1_2+1_2=0_2\). This is because 1 + 1 is in fact the value 2, which is \(10_2\), so we “overflow” our digit’s place (one’s place) and carry out a 1 to the next digit’s place, the two’s place.
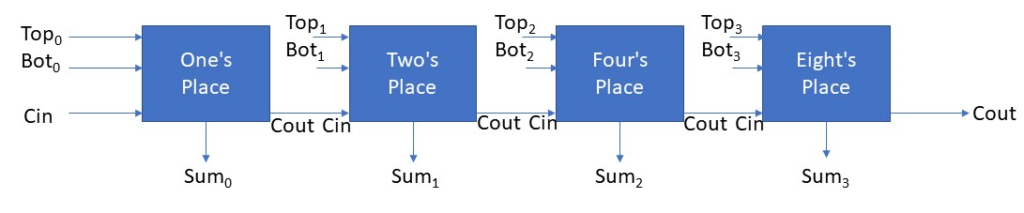
Carry
Notice that the truth table above has a carry out as an output and a carry in as an input. These adders are connected together, and there is one adder per digits place. So, they are connected together. The carry out of the one’s place will then be the carry in input to the two’s place. The carry out of the two’s place will then be the carry in input to the four’s place. This goes on and on. For integers, there are 32 of these connected together–one for each bit. For longs, there are 64 of these connected together–again, one for each bit.
Example
Perform \(1011_2 + 0101_2\).
111 <--- carry out 1011 <--- top operand (11) + 0101 <--- bottom operand (5) ----- 10000 <--- result (16)
Overflow
You can see in the example above that we come back with a 5 digit number. For math on paper, this is fine since we have an infinite number of digits. In a computer, we aren’t given infinite digits–there are only so many transistors we can fit. If we require more digits than are available, we call this condition an overflow. Sometimes an overflow is good, as you’ll see with adding a negative number in two’s complement format. Other times, it completely skews our number since we’ve effectively lost a digit.
In several arithmetic and logic units, they output four flags in addition to the result. The flags are abbreviated as NZCV, where N is “negative”, Z is “zero”, C is “carry”, and V is “overflow”. The difference between carry and overflow is that carry is for unsigned data types and overflow is for signed data types. Essentially in this case, the term overflow means that we could have possibly moved the sign bit out of place, hence changing the number from a positive to negative or from a negative to a positive.
Adding Negative Numbers
Recall that negative numbers are stored in two’s-complement format, meaning that we flip all of the bits and add 1. One neat detail about two’s complement is that we can add normally to it and get the correct result. For example, let’s add -7 and 6. We should get -1. Since we’re using two’s complement we need a data size…remember the most significant bit (leftmost) determines if a number is negative.
$$-7_{10}=\text{~}0000\_0111_2+1=1111\_1001_2$$
AND
$$6_{10}=0000_0110_2$$
1111 1001 <--- top value (-7) + 0000 0110 <--- bottom value (6) --------- 1111 1111 <--- result (-1)
We can see that the result is all 1s using 8 bits. This signifies that this is a negative number. So, let’s see its magnitude: \(\text{~}1111\_1111_2+1=0000\_0000+1=1\). So, our answer is -1. -7 + 6 is indeed -1. With the two’s complement system, we just need to add normally!
Subtraction
Subtraction is much easier done by just taking the two’s complement of the right (or bottom) operand and adding. In fact, most adders are built to do just this. For example, 8 – 4 is identical to 8 + -4. We’ll use that to our advantage.
Using binary arithmetic, what is 8 – 4?
1111 <--- carry 0000 1000 <--- 8 + 1111 1100 <--- -4 --------- 0000 0100 <--- 4
With our carry, notice that we keep carrying until we run out of digits. This is one example where we use overflow to our advantage, and it is one reason that two’s complement works!
Multiplication
Multiplication follows all of the same rules in binary that it did in decimal. However, it’s much simpler because we’re only multiplying 1s and 0s–the two easiest numbers to multiply. However, there is a “trick” because we’re using 1s and 0s. Much like the trick where if you see trailing zeroes, you can just write those down without having to go through the long-hand math.
Using binary arithmetic, multiply 8 and 4.
0000 1000 <--- 8
x 0000 0100 <--- 4
---------
0000 0000 <--- one's place
00000 0000 <--- two's place (add a 0)
+ 000010 0000 <--- four's place (add two 0s)
-----------
0010 0000 <--- result
Notice that we can think of these as decimal numbers when performing arithmetic on paper. You can see that when we multiply 8 and 4, we get the value 0b10_0000, which is 32. Let’s take at an algorithmic version of this. Since we’re dealing with just 0s and 1s, we’re making a decision to add the multiplicand or not. The multiplier makes the decision. If there is a 1 in the digit’s place that we’re looking at, we add the multiplicand. If there’s a 0, we skip and move on to the next digit’s place.
Take a look at each one of the three results we get for the example above. If we perform a left shift on the top number, we go from 1000 to 10000 to 10000. Notice this is a way where we can add a zero to the right of the number.
So, when do we stop? Well, we will keep adding the top number as long as there is a 1 in the digit’s place we’re looking at (starting at the one’s, moving to the two’s, the four’s, and so on). So, whenever the bottom number only contains zeroes, we no longer have to keep adding the top number. This will be your condition to end multiplying.
Notice that when we multiply, we may well exceed the size of our original data size. In most systems, we require two-times the size of the original. In Intel/AMD, after multiplication, two registers were used to hold the product. With 64-bit systems, we don’t worry as much because 64-bits can hold a lot of information. However, if you don’t take care with your data sizes, multiplication can easily lead to overflows.
In multiplication, we generally only multiply positive numbers. This means we only need one multiplication function for both signed and unsigned numbers. Before we send our multiplier and multiplicand to that function, however, we need to check the most significant bit. If it’s 1, we take the two’s-complement and remember that we saw a negative number. Recall that in arithmetic, if we multiply a negative with a positive, we get a negative result. In essence, if we multiply like signs, we get a positive product, otherwise we get a negative product.
bool multiplier_negative = ((multiplier >> 31) & 1) == 1;
bool multiplicand_negative = ((multiplicand >> 31) & 1) == 1;
bool result_negative = false;
if (multiplier_negative) {
multiplier = twos_complement(multiplier);
result_negative = !result_negative;
}
if (multiplicand_negative) {
multiplicand = twos_complement(multiplicand);
result_negative = !result_negative;
}
int product = multiply(multiplier, multiplicand);
if (result_negative) {
product = twos_complement(product);
}
return product;
The code above checks the sign bit of a 32-bit multiplier and multiplicand to see if they’re negative. Then, we take the two’s-complement of any negative values. We could easily use the – (negation) operator, but I want to show what’s happening here. We run our now positive values through the multiply function to get a product. Before we’re done, we need to see if our product needs to be negative based on the two operands.
Division
There are several division algorithms, including restoring division, non-restoring division, and repeated subtraction. We will be discussing the easiest, which is the repeated subtraction algorithm. Essentially, we keep subtracting the divisor from the dividend. Whatever is left when the dividend < divisor is called the remainder. The number of times we subtracted the divisor from the dividend is the quotient.
Example
Divide 17 by 7.
17 - 7 = 10 - 7 = 3
We were able to subtract 7 twice, and what was left over was 3. So, the quotient is 2 and the remainder is 3.
struct Result {
unsigned int quotient;
unsigned int remainder;
bool divide_by_zero;
};
Result divide(unsigned int dividend, unsigned int divisor) {
if (divisor == 0) { return {0, 0, true}; }
Result result = {0, dividend, false};
while (result.remainder >= divisor) {
result.quotient += 1;
result.remainder -= divisor;
}
return result;
}
Restoring Division
One binary algorithm for dividing two integers is called restoring division. This allows for a quotient and a positive remainder. There are other algorithms that allow for negative remainders, but we’re used to positive, so we’ll learn the restoring division algorithm.
Just like repeated subtraction, we need to make a test of the operands to see if we are divisible or not. Recall that in long-division we add the next place if the digit’s place is not divisible. We do the same with restoring division.
struct Result {
unsigned int quotient;
unsigned int remainder;
bool divide_by_zero;
};
Result restoring_divide(unsigned int dividend, unsigned int divisor) {
if (divisor == 0) { return {0, 0, true}; }
Result result = {0, 0, false};
long Remainder = dividend; // Use capital R to signify its increased capacity
long Divisor = static_cast<long>(divisor) << 32;
// Now, we go bit-by-bit to see what each digit's place gets (a 1 or a 0)
for (int i = 31;i >= 0;i--) {
Remainder = (Remainder << 1) - Divisor;
if (Remainder >= 0) {
result.quotient |= 1 << i; // set bit i
}
else {
Remainder += Divisor; // restore the divisor
}
}
result.remainder = (Remainder >> 32);
return result;
}
The restoring division algorithm is based on the following division recursive formula:
$$R(i+1)-D\times 2^i=R(i)$$
This is why we need an IF statement. The if statement checks this relationship. If we’re wrong, then we have to add (restore) the divisor. Otherwise, we set the bit to 1 of that digit’s place, and hence mark its (partial) magnitude. You probably recognize the \(2^i\). This is essentially a left shift. This is why we need to store the divisor left shifted by 32 places long D = static_cast<long>(divisor) << 32;, since when we’re at digit index 31, \(2^i\) will start at bit index 32. We need to static cast this because an integer shifted left 32 places will overflow and always be zero.
Restoring division is much more efficient than repeated subtraction. In fact, on some tests (that I quickly did on my computer), restoring division is 10 times more efficient.
Data Type Widening and Narrowing
Putting a smaller data type into a larger data type, such as an integer into a long, is called widening. Whereas putting a larger data type into a smaller data type is called narrowing. When we narrow, we just take the least-significant bits. For example, if we narrow an integer into a char, we take the LOWER 8 bits from the integer (indices 0 through 7). This obviously can change the original value considerably. Widening can be done in one of two ways: sign-extension or zero-extension. What this means is that we need to add bits, so how do we do that? A sign extension replicates the sign bit (most significant bit) of the smaller data type into the larger data type. This is the default in C++ for all signed data types. A zero extension just means we add zeroes to pad a smaller number into a larger number. This is the default in C++ for all unsigned data types.
Examples
What is the value of i when the following occurs? int i = static_cast<char>(-8) ?
-8 as a char is 8 bits, which is 0b1111_1000. ALWAYS ignore the left hand sign of the equals sign. It doesn’t matter until everything to the right has been completed. So, (char) -8 will narrow -8 (which is an integer literal). Then, when we set it equal to int i, it will widen back to 32 bits. Now, we need to consider if this is going to be a sign-extension or zero-extension. Remember that if we’re widening FROM a signed data type, it’ll sign extend. Well, by default all integral data types are signed, so we widen -8 using sign extension. We know we need to go from 8 bits to 32 bits and that sign-extension means to duplicate the sign bit.
In this case, the leftmost bit of -8 as a char is 1, so we will replicate 24 1s to widen an 8-bit value to a 32-bit value: \(1111\_1000_2~\rightarrow~1111\_1111\_1111\_1111\_1111\_1111\_1111\_1000_2\). We can take the two’s complement to see that this is still the value -8. Negative numbers’ values do not change as long as we add 1s in front of them, much like adding 0s in front of a positive number doesn’t change its value.
Let’s do the same thing, except zero extend it to see what happens. So, we need to change what we’re storing into: int i = static_cast<unsigned char>(-8);
In this case, we’re widening from an unsigned data type. Remember, it doesn’t matter what we’re going INTO, just FROM. So, this will cause C++ to zero-extend -8 into 32-bits:
$$-8_{10}=1111\_1000_2\rightarrow 0000\_0000\_0000\_0000\_0000\_0000\_1111\_1000_2$$
If we look after zero extension, we essentially made -8 into 248 (128+64+32+16+8). This is why it is VERY important to know if we’re sign extending or zero extending. Luckily, the rules are simple. Notice that even though we’re going INTO a signed integer it still zero-extended. It only matters what we’re coming FROM. The only change I made between these examples is that I cast -8 as an unsigned char to zero-extend whereas casting -8 as a signed char sign-extends.
When we get into assembly, it is very important to know what the machine is going to do. Some machines default to sign-extending, others default to zero-extending, and some mix both–just to be confusing :).
Video
IEEE-754 Floating Point
IEEE-754 is just a fancy name for a standard that tells you (and the computer) how to arrange 32-bits or 64-bits. In this case, it’s how you arrange these bits to allow for scientific notation, which is how we float the decimal. We can move the decimal place left by decreasing the exponent, or we can move the decimal place right by increasing the exponent. The following equations show how the exponent affects the decimal’s location.
\(\)$$1.23\times~10^3=1230$$
$$1.23\times~10^{-3}=.00123$$
As you can see here, there are three (3) fields that IEEE-754 defines: (1) a sign (0 = positive, 1 = negative), (2) an exponent, and (3) a fraction. The sign is either a 0 or 1, and it DOES NOT follow two’s complement. There is a -0 and a +0. The exponent is the exponent of base 2. The fraction is everything to the right of the decimal point. So, \(1.234\times~10^7\) would have a sign of 0 (positive), an exponent of 7 (not exactly, but stay with me so far), and a fraction of .234. This is all the information we need. Keep in mind that .234 is base 10. All IEEE-754 formats describe base 2. Just like x 10 to some power floats the decimal in base 10, if we multiply by 2 to some power, we can float the decimal in base 2. All IEEE-754 defines is scientific notation!
The exponent has a bias, which allows an unsigned number to have negative values. The exponent itself is an unsigned number. The 32-bit and 64-bit formats have different biases.
Take a number \(1.1101\times2^1\). Just like base 10, in base 2, when we multiply by 2, we move the decimal either right or left. So, the number becomes \(11.01_2=3.25_{10}\). In IEEE-754, the number must be 1.something. This is called normalized. So, we can’t store 11.01 with an exponent of 0, we must store 1.101 with an exponent of 1. This is fairly easy to do by just adding or subtracting from the exponent until the decimal is directly after the 1. This gives us more bits to store in the fraction portion.
32-bit IEEE-754
In C++, the 32-bit IEEE-754 number is used by the float data type in C++. In here, the 32-bits are arranged as follows.

When we talk about a bias of 127, we mean that if we look at the 8-bit exponent in the 32-bit format, it’s going to be 127 bigger than the actual exponent. So, if we want to figure out the actual exponent, we’d subtract 127. Say we had an exponent of \(1001\_1100_2=128+16+8+4=156_{10}\). So, we have a biased exponent of 156. We then subtract 127 from 156 to get the actual power of 2: \(156-127=29\). This means our number is \(1.\text{fraction}\times 2^{29}\). The fraction is copied directly from the last 23 bits of the number. Recall that this is everything to the RIGHT of the decimal. The 1. portion is implied and is not explicitly in the 32-bits.
32-bit Example
Convert the following 32-bit number into decimal: 0x418e_0000.
First, we need to convert this into binary so we can parse out the 1-bit sign, 8-bit exponent, and 23-bit fraction:
$$418e\_0000_{16}=0100\_0001\_1000\_1110\_0000\_0000\_0000\_0000_2$$
The first bit is 0, which is a positive number. The next 8-bits are \(1000\_0011_2=128+2+1=131_{10}\), and the last 23-bits are \(.000111_2\). Since everything to the right of 0, we can ignore it. Just like 1.230 and 1.23 are identical, the same holds true for base 2.
Our exponent is 131, so we subtract the bias 127 to get an exponent of \(131-127=4\). The fractional portion was \(.000111\), and we have an implied 1., so we have \(1.000111\times 2^4\). Recall that a positive exponent moves the decimal right. In this case, it moves it to the right by four places. To remind yourself which way the decimal goes remember, bigger exponent means bigger number.
$$1.000111_2\times 2^4=10001.11_2$$
Now, we convert to base 10. Look to the left of the decimal first, \(10001_2=16+1=17_{10}\). Then, look to the right of the decimal: \(.11_2=0.5+0.25=0.75_{10}\). Putting the numbers together gives us \(17+0.75=17.75\).
So, 0x418e_0000 is the decimal value 17.75F.
Another 32-bit Example
Convert -81.0625 into 32-bit, IEEE-754 in hexadecimal.
Going the opposite direction still requires us to find three things: sign, exponent, and fraction. So, as always, first step: convert to binary.
\(-81.0625_{10}=-1010001.0001_2=1010001.001_2\times 2^0=-1.010001001_2\times 2^6\).
So, now we have it in binary and in normalized notation, that is 1.something. Now all we have to do is grab the sign, bias the exponent, and write down the fraction.
Sign = \(\text{negative}=1\)
Exponent = \(6+127=133_{10}=1000\_0101_2\)
Fraction = \(0100\_0100\_0100_2\)
So, the sign comes first, followed by the exponent, and finally the fraction–remember to keep adding zeroes until you get 23 total bits for the fraction.
Sign Exponent Fraction [1] [1000 0101] [0100 0100 0100 0000 0000 000] 1100 0010 1010 0010 0010 0000 0000 0000 C 2 A 2 2 0 0 0
So, -81.0625 is 0xc2a2_2000 in 32-bit, IEEE-754 format.
64-bit IEEE-754 Format
The 64-bit IEEE-754 format can be used in C++ by using the double data type. You will see that a double doesn’t double every field, but instead gives you a somewhat bigger exponent, but a MUCH larger fraction space.
We still have three different fields: sign, exponent, and fraction, yet we have double space. Interestingly enough, the largest expansion is the fraction. The exponent only goes from 8 bits in 32-bit format to 11 bits in 64-bit format.

64-bit IEEE-754 Examples
Convert 0xc054_4400_0000_0000 into decimal.
We need to parse out the three fields, so as always, convert to binary:
C 0 5 4 4 4 0 0 0 0 0 0 0 0 0 0 1100 0000 0101 0100 0100 0100 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000
We then pick out our 1-bit sign, 11-bit exponent, and 52-bit fraction:
Sign = 1 = negative
Exponent = \(1000\_0000\_101_2=1029-1023=6\)
Fraction = \(1.0100\_0100\_01_2\)
You can see that I already subtracted the 64-bit bias (1023) to get an exponent of 6, and I already added the implied 1. to the fraction. So, now our number is as follows.
$$-1.0100\_0100\_01_2\times 2^6=-1010001.0001_2=-81.0625_{10}$$
So, 0xc054_4400_0000_0000 is the value -81.0625.
Another 64-bit IEEE-754 Example
Convert 17.75 into 64-bit, IEEE-754 format in hexadecimal.
First, convert to binary: \(17.75_{10}=10001.11_2\). Then, normalize the value: \(10001.11_2\times 2^0=1.000111_2\times 2^4\). So, now we have our sign (0=positive), our exponent (4), and our fraction (.000111). Now, bias our exponent by adding \(4+1023=1027_{10}=100\_0000\_0011_2\).
Sign Exponent Fraction [0] [100 0000 0011] [0001 1100 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000] 0100 0000 0011 0001 1100 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 4 0 3 1 C 0 0 0 0 0 0 0 0 0 0 0
So, 17.75 is 0x4031_c000_0000_0000 in 64-bit IEEE-754 format.
C++ Float/Double
C++ literals are different for float and double. The literal 1.0 is a double, whereas 1.0F is a float. This allows a programmer to tell C++ whether they want a 64-bit or 32-bit floating point data type.
Video
Floating Point Arithmetic
Floating-point is just scientific notation. We have a number multiplied by 2 to some exponent (for base 2 numbers). So, just like how we added and multiplied with scientific notation, base 10, we do the exact same with scientific notation, base 2.
Addition
When we add, we must make sure that the decimal place is lined up and that we have identical exponents for both numbers. Then, our result has the exact same exponent. However, we may need to re-normalize. Recall normalized numbers start with 1.something.
Perform \(10.11_2\times 2^3+101.111_2\times 2^2\).
For this problem, we must make sure that our powers are identical. We can either go with the exponent 2 or 3. It doesn’t matter. We are only required to be consistent. I’m going to choose 2.
$$10.11_2\times 2^3 \\ + \\ 101.111_2\times 2^2$$
Now, we rearrange the number by making both exponents 2. We could even make them both 0, but changing one number is easier than both. So, 0b10.11 becomes 0b101.1. Also, notice that the second number has 6 digits. We can pad this out by adding zeroes to the right of the decimal, which doesn’t change its value but gives us 6 digits from 4: 0b101.100.
$$101.100_2\times 2^2 \\ + \\ 101.111_2\times 2^2 \\ = \\ 1011.011_2\times 2^2$$
We can double check our answer by noting that \(101.1_2\times 2^2=10110_2=22.0_{10}\) and \(101.111_2\times 2^2=10111.1_2=23.5_{10}\). Therefore, \(22.0_{10}+23.5_{10}=45.5_{10}\). Looking at our result in base 2, we get \(1011.011_2\times 2^2=101101.1_2=32+8+4+1+0.5=45.5_{10}\). Hence, our arithmetic was correct.
Subtraction
Add 0x40f8_0000 with 0xc010_0000, give your answer in 32-bit IEEE-754 hexadecimal.
This will be the most complex question you’ll be asked for floating point arithmetic. Essentially, we’re the computer. We have two values in IEEE-754 format, we need to perform an operation, then store it back as IEEE-754. There are many places that can go wrong here, so we have to be careful and always check our results!
First, let’s convert to something we recognize, binary.
\(40\text{f}8\_0000_{16} = 0100\_0000\_1111\_1000\_0000\_0000\_0000\_0000_2\)Sign = 0 = positive
Exponent = \(1000\_0001_2=128+1=129_{10}-127_{10}=2_{10}\)
Fraction = \(1.1111_2\)
\(40\text{f}8\_0000_{\text{IEEE754}}=1.1111_2\times 2^2\)
Sign = 1 = negative
Exponent = \(1000\_0000_2=128_{10}-127_{10}=1_{10}\)
Fraction = \(1.001_2\)
\(\text{c}010\_0000_{\text{IEEE754}}=-1.001_2\times 2^1\)
$$1.1111_2\times 2^2 \\ + \\ -1.001_2\times 2^1$$
Now, we need to match exponents. I’ll go with 1, but 2 is just as good.
$$11.111_2\times 2^1 \\ + \\ -1.001_2\times 2^1$$
Uh oh! We have a negative number. Remember that we used two’s complement to add two numbers together that were negative. We can do the same here, however we need to keep track of how many digits we need. Recall that when we add a negative number, two’s complement wouldn’t work if we had an infinite precision. To do this, we can ignore the decimal point since we’re just flipping 0s and 1s. We also will drop down the exponent 2^1, so we don’t need to deal with that here.
$$\text{~}01.001_2+1=10.110_2+1=10.111_2\rightarrow 10.111_2\times 2^1$$
So, now we just add as usual with the two’s complement version (which is negative). Notice that I chopped us off at 2 digits to the left of the decimal. We could expand this farther adding 1s, which would keep adding 1+1. This is why I say it’s important to know how many digits we need because on paper, we have an infinite number of digits, unlike in IEEE-754.
$$11.111_2\times 2^1 \\ + \\ 10.111_2\times 2^1 \\ = \\ 10.110_2\times 2^1=101.10_2=5.5_{10}$$
We can double check our answer by looking at 0b111.11, which is 7.75 and -0b10.01 which is -2.25. When we add these two, we get 5.5.
Now, to convert this back into IEEE-754. We need a sign, this is positive, an exponent, which we won’t know until we normalize our number, and a fraction, which we also won’t know until we normalize our number.
$$101.1_2\times 2^0=1.011_2\times 2^2$$
So, our exponent is 2, which we add the bias, 127, to get 129, which is \(1000\_0001_2\). The fraction is 011 and the sign is 0 (positive). Now, we have all the information we need to put together a 32-bit IEEE-754 number:
Sign Exponent Fraction [0] [1000 0001] [0110 0000 0000 0000 0000 000] 0100 0000 1011 0000 0000 0000 0000 0000 4 0 b 0 0 0 0 0
So, our final answer is 0x40b0_0000, which is +5.5 in IEEE-754 format. Let’s recap. We can use two’s complement–but we ignore the decimal point and add 1 starting at the rightmost digit, even if that’s a fractional digit. Then, we have to keep track of how many digits we need. If we see a 1+1=0 carry the 1 repeating over and over again, we can be assured that we don’t need any more digits.
Multiplication
Multiplying scientific notation means you add the exponents, ignore the decimal, and multiply as if it was one big number. Afterward, you figure out how many decimal points the product needs–remember to count all of the digits to the right of the decimal.
What is the product of \((110.1\times 2^{-1}) \times (10.1\times 2^1)\).
$$110.1_2\times 2^{-1} \\ \times \\ 10.1_2\times 2^1 \\ = \\ 001101_2 \\ + \\ 110100_2 \\ = \\ 1000001_2\times 2^0$$
So, now we count the number of digits to the right of all decimal points, which we can see are two. So, we move the decimal point left two places:
$$10000.01_2\times 2^0=16+0.25=16.25_{10}$$
Multiplication is fairly straightforward. No need to align decimal points. In fact, we ignore them until the very end. Also, remember that we always multiply positive numbers and then figure out the sign later. So, no two’s complement anywhere in here.
We can check our answer because 0b11.01 is 3.25 and 0b101 is 5. \(5.00_{10}\times 3.25_{10}=16.25_{10}\). So, when we multiply as usual, we get the same values!
Convert your answer into 64-bit, IEEE-754.
64-bit has a 1-bit sign, 11-bit exponent, and 52-bit fraction. So, we have \(10000.01_2 \times 2^0\). Remember that this needs to be normalized before we determine our exponent and fraction, which gives us \(10000.01_2 \times 2^0=1.000001_2 \times 2^4\). So, our fraction is 0b000001, and our exponent is \(4+1023_{bias}=1027_{10}=100\_0000\_0011_2\). Recall that the 64-bit IEEE-754 bias is 1023.
Sign = positive = 0
Exponent = 1027 = 0b100_0000_0011
Fraction = 000001
Sign Exponent Fraction [0] [100 0000 0011] [0000 0100 0000 ... 0000] 0100 0000 0011 0000 0100 0000 ... 0000 4 0 3 0 4 0 ... 0
This gives us a hexadecimal value of 0x4030_4000_0000_0000.
Video
Widening and Narrowing
When we have two numbers of different size, such as an integer and a long, something has to happen to make them the same size, otherwise we cannot perform arithmetic on them. The same can be said when we take a larger data type, such as a long, and squeeze it into a smaller data type.
Widening
When we need to make a smaller data type a larger data type, we call it widening. To widen a value, we have two choices: (1) zero-extend or (2) sign-extend. A zero-extension means that we add zeroes in front of the number to pad it out to the size we want.
For example, say we have an 8-bit number \(10101010_2\) and we want to widen it into a 16-bit number. For zero-extension, we would have to add 8 zeroes to the front of the number. Recall that \(0011_2\) and \(11_2\) are both the value 3. So, by adding zeroes in front of the number, we keep the value the same, but we just expand it.
The second way to widen is to sign-extend. A sign-extension is required for signed data types. Recall that we use the leftmost bit to denote the sign where 0 is positive and 1 is negative. If we zero extend, we will always end up with a positive number. So, instead, with a sign-extension, we take the sign of the number and extend that. So, for positive numbers, we essentially zero-extend, but for negative numbers, we one-extend.
For example, the following 8-bit number is -1: \(11111111_2\). However, zero-extended, it is now the value 255 \(0000000011111111_2\), but if we sign-extend, we still end up with -1: \(1111111111111111_2\).
In C++, unsigned sources are zero-extended, whereas signed sources are sign-extended.
int main() {
unsigned char a = -5;
char b = -5;
int c = a;
int d = b;
printf("%d %d", c, d);
}
The code above will print 251 -5. You can see that a zero-extended when it was widened into c, and b sign-extended when it was widened into d. Recall that the source operand (a and b) determines the widening operation in C++, NOT the destination.
Narrowing
We can see that in the case of taking a smaller data type into a larger data type, we have a choice to zero or sign extend. However, going from a larger data type into a smaller data type, we always truncate the value by taking the least significant bits. So, if we have a short and want to put it into a char, we would take the lower (rightmost) 8-bits, which would truncate the upper 8-bits. Yes, data can obviously be lost, but this way, we at least have a chance if the number is less than what can be stored in the destination data type.