| No previous chapter | Table of Contents | Binary Numbers |
Contents
What is Computer Organization?
Computer organization and computer architecture seemingly describe the same things, however in this book, we will distinguish organization as how the computer components are put together to create what we call a computer in this context. We then distinguish architecture as being the decisions and designs to create those components. In other words, architects design the components that will be organized together to make a computer.
The Covers
A computer that we interact with either through our mobile phone, desktop, or laptop is split between its hardware, which are the physical components routing electrons, and its software, the instructions written to perform an operation.
Computing really is just instructing the CPU. We can work with data, but software is just instructing the hardware.
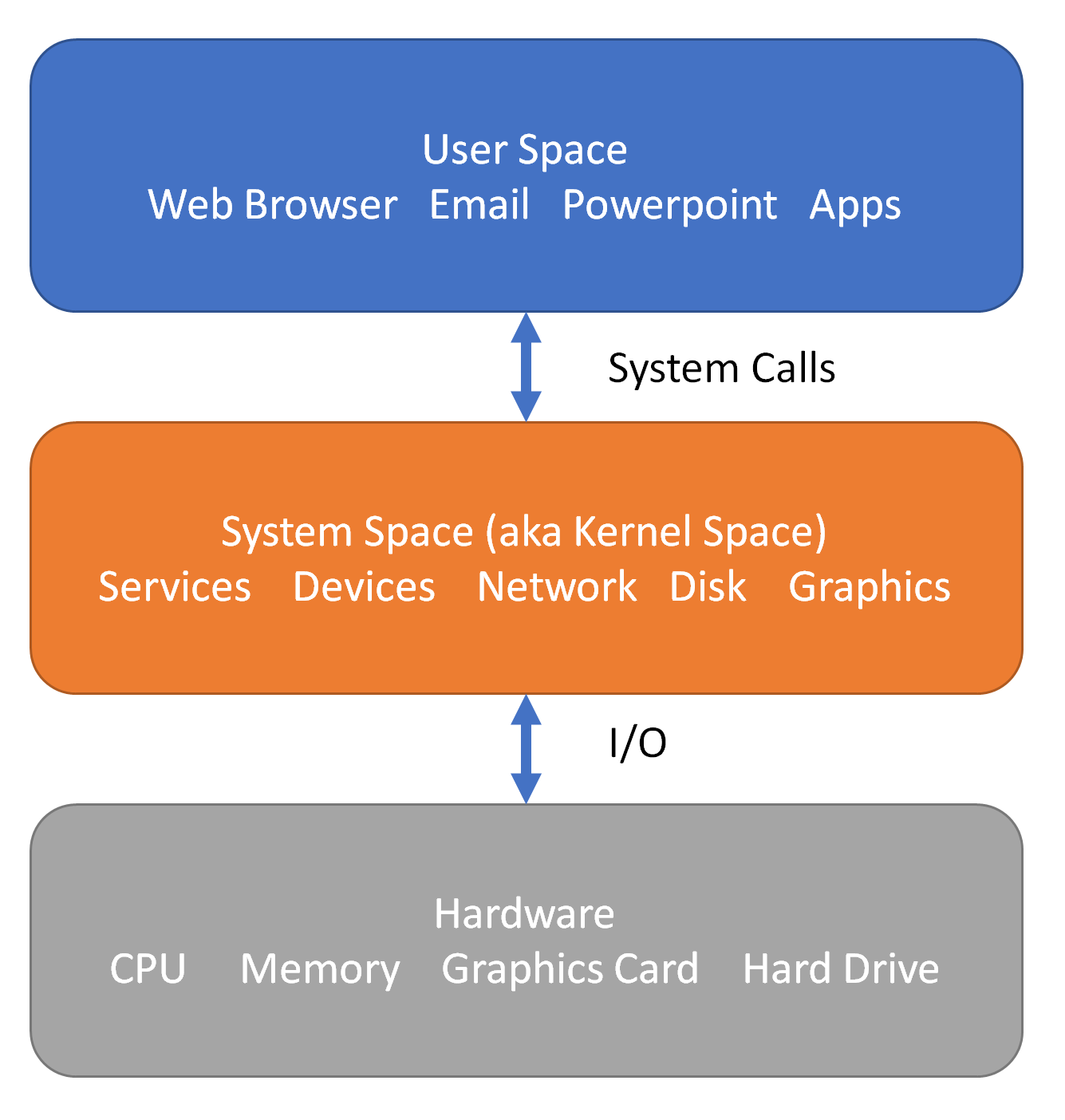
Software Abstraction
Abstraction is a way to minimize the knowledge of the underlying system. For example, someone doesn’t have to know how a car’s engine works to drive it. Instead, the engine itself is abstracted away from the user. Instead, when we push the pedal, a series of things happen to get the engine to increase in speed and eventually move the car forward. This is the same with a computer. When we press a key on the keyboard, a series of things happen. However, to use a computer, we don’t actually need to know how the keyboard works–just that it does.
Operating System
The software side of a computer can be split into two (or more) ways: (1) user space and (2) system space. The operating system, such as Linux or Windows or Mac OSX runs in system space, whereas user applications generally run in user space. The CPU usually has two types of instructions: (1) unprivileged, such as add, subtract, multiply, and divide and (2) privileged, such as control register read/write.
The operating system is itself an abstraction. When we open a file in C++, we are asking the operating system to look at the system, locate the file, and open it for us. Again, as the C++ programmer, we only need to know how to use the interface, and not the underlying file system, where the file is located, or really anything like that.
Under The Covers
If we take off the case or open the cell phone, we will see a circuit board sometimes referred to as the motherboard. This used to be the go-to name for desktops, but it isn’t as commonly used for embedded or mobile systems, but if you say motherboard, we know what you mean.
The underlying hardware is a combination of several digital logic components. That is, they are wires that connect to transistors to be read as 0s and 1s. We will cover basic digital logic later, but for now, just know that all the components we talk about below operate on the digital concept–again, 1s and 0s.
Motherboard
The motherboard is a single board that connects all of the components of the computer. The board is responsible for routing data and power throughout the entire system. Most PC motherboards also include a basic input/output system (BIOS). This allows you to configure things, such as the what hard drive to boot, and so forth. All of these things are connected to a central controller known as the central processing unit (CPU). This is the brain of the computer, and it contains several components inside as well.
Central Processing Unit (CPU)

The x-ray above shows 4 operating cores. Each core contains lower levels of cache, an arithmetic and logic unit, memory management unit, integer and floating-point registers, and a floating point unit. The CPU shares a system agent, which contains the memory controller and display engine. Finally, a shared level 3 cache (if available on the given CPU), and the I/O controller are located inside of the CPU.
Components
The components inside and outside of the CPU that we will be covering in this course are:
- Inside the CPU
- CPU instructions
- Cache (L1/L2 per core, common L3)
- Pipelining (per core)
- Memory management unit (per core)
- Arithmetic and logic unit (ALU) (per core)
- Floating point unit (FPU) (per core)
- Register file (per core)
- Memory and I/O controller (common)
- Outside the CPU
- Dynamic and static random access memory (DRAM/SRAM)
- Instruction memory
- Data memory
- I/O busses (PCIe, USB)
- Memory-mapped and port I/O (MMIO and PIO) devices
- Block and character I/O devices
- Chipset
- Direct Memory Access (DMA)
- Dynamic and static random access memory (DRAM/SRAM)
Architecting Computers
Computer architects have invested many years in coming up with how to improve performance, reduce size, reduce cost, and improve usability when it comes to computers. Since computer operate using digital logic, we have to design how electrons flow from a voltage source through several transistors which route electrons to their destination.
More Transistors in a Smaller Space
Moore’s Law is an observation that sees transistors in a computing unit double every two years. The die that the CPU is cast on is getting smaller and smaller, with transistors seen more densely packed. More transistors means more functions we can do inside of a CPU. We can only reduce circuits so much, but at some point we need transistors to route electrons.

The physical distance between the CPU and the components it controls is becoming an issue. We all think that the speed of light, which is also the speed of electrons, is suuuuper duuuper fast, however with the fast clock rates, the electrons have to be in place before the next clock cycle.
For example, say we have a 3.5 gigahertz (GHz) clock speed in our CPU. This means that there are 3.5 billion cycles per second. We also know that the speed of light is about 300 million meters per second. Doing simple math, we can see that each cycle, electrons only have a chance to move about: \(\frac{300,000,000}{3,500,000,000}=\frac{3}{35}=0.09~\text{meters}=90~\text{millimeters}~\approx~3.5~\text{inches}\).
So, making transistors more compact and smaller can help with this physical limitation. Unless and until we can find a way to move electrons faster, we are stuck with moving components closer. Making components smaller helps get closer to this goal, but there are still physical limitations regarding placement of components.
Design Around the Most Likely Cases
A general purpose computer means that the architects must think about what tradeoffs to consider. One such research topic was what were the most likely cases in a computer. This was done by profiling running machine code and seeing which instructions are most frequently used. One such instruction was called a branch instruction, which is a fancy term for a condition–such as an if statement or while loop condition. These are very common instructions, so it would make sense to try to improve these.
The Intel/AMD processor has been extended many, many times. It started as a 16-bit CPU, it grew to a 32-bit CPU, and now it is a 64-bit CPU. The 16-bit and 32-bit still exist inside even the newer 64-bit CPUs! There are also extensions that speed up encryption routines, or vector mathematics, and so forth.
Designing a CPU to be general doesn’t mean that the architects can’t improve certain areas. The RISC-V architecture supports extensions because when the instruction set architecture was designed, they knew that it needs to be able to target general purpose computing as well as domain-specific computing, such as Bitcoin mining, or servers.
| RISC-V Extension | Description |
|---|---|
| A | Atomic instructions. Atomic means an instruction that cannot be interrupted. |
| C | Compressed instructions. Instructions that are 16 bits instead of 32. |
| D | Double-precision floating point. |
| F | Single-precision floating point. |
| I | Integer arithmetic instructions, such as add, sub, load, store, etc. |
| M | Hardware multiply and divide. Multiply and divide can be implemented in software for smaller, embedded systems, but systems with M mean it is implemented in hardware. |
As you can see with the table above, a CPU designer can pick and choose the extensions to target their general purpose CPU and/or domain-specific CPU.
Doing More at the Same Time
There are several components in a computer, however think about when the CPU executes an instruction: (1) it has to retrieve the instruction from memory, (2) it has to decode the instruction and set the parameters based on the instruction, (3) it has to execute the instruction, and (4) it has to store the result somewhere.
You can see that there are about four steps here, but each step involves a different section of the CPU. So, why not fetch the next instruction while the current instruction is being decoded by the CPU? In fact, most CPUs do something like this, which is called pipelining. We will discuss pipelining later in this course.
Doing more things simultaneously is called parallelism. There are three types of parallelism that we will discuss in this course: (1) instruction-level parallelism (pipelining), (2) data-level parallelism (single-instruction, multiple-data [SIMD]), and (3) thread-level parallelism (threading).
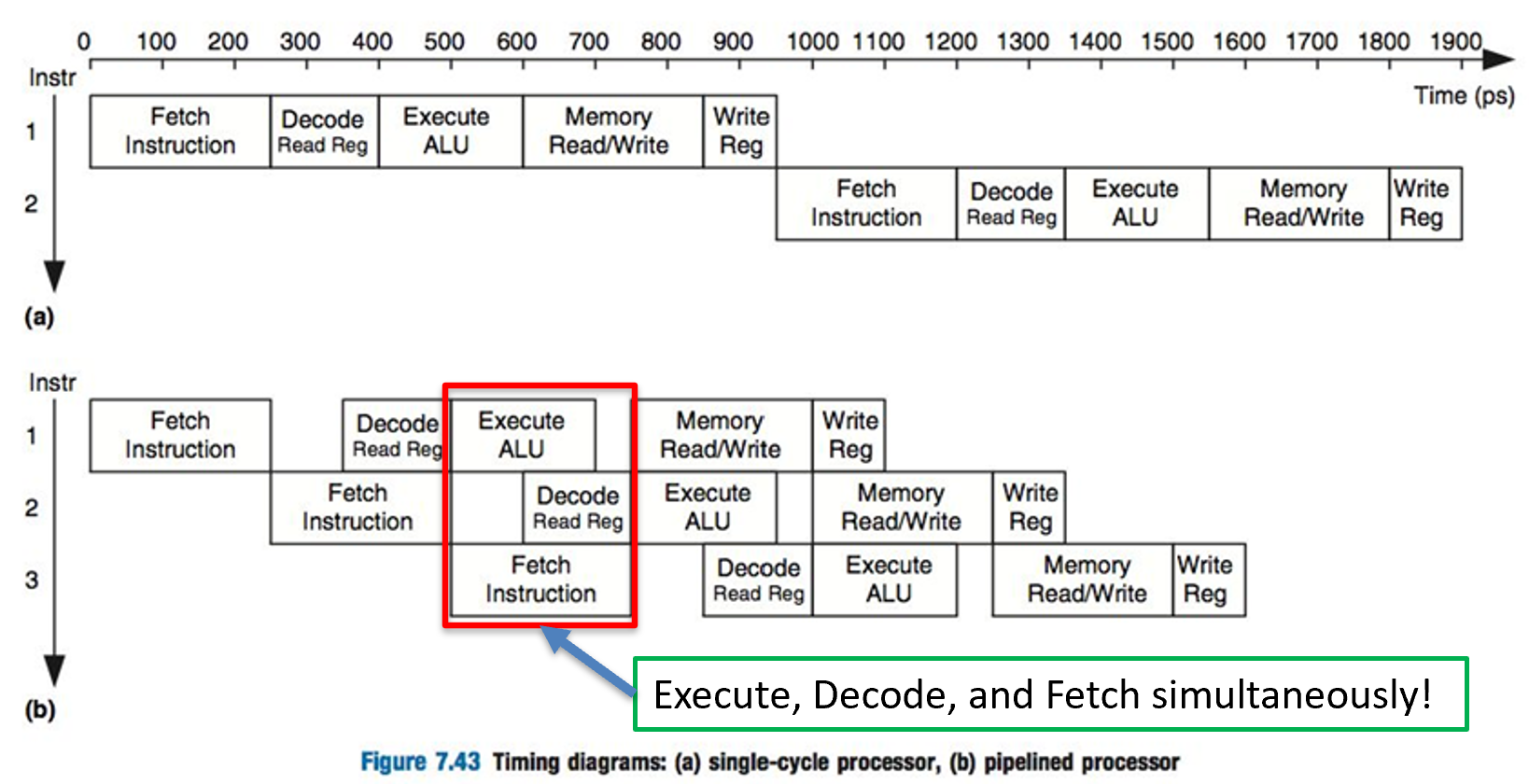
The image above shows a pipelined process of washing, drying, and folding laundry. As you can see above, all four loads of laundry (A, B, C, and D) are finished around 10:00pm. The diagram below shows an unpipelined, serialized processor. Notice how long it takes to do the same amount of laundry.

Predicting the Future
Recall that earlier we looked at the most common instructions, and the branching instructions came up. Branches have two choices, but only one needs to be fetched by the CPU. So, what happens if we choose the wrong branch? Well, we ruin the performance boost of pipelining. So, how about we predict the future? It’s not purely predicting the future, but the CPU can store how many times a branch took choice A versus choice B. If A is more likely, why not load that instruction? This is a concept known as speculation.
Memory Hierarchy
Memory is physically located away from the CPU, and in many systems, the RAM is several inches away from the CPU. Recall that electrons move at the speed of light, so with fast processor clocks, we can’t go beyond a few inches. Otherwise, the electrons simply don’t have enough time to make it to their targets.
The CPU has memory built inside of it known as registers. This is where the terms, 16-bit, 32-bit, and 64-bit processors came from. If these small pieces of memory store 16 bits, then it’s a 16-bit machine, if they store 32 bits, then it’s a 32-bit machine, and finally, if they store 64 bits, it’s a 64-bit machine. As you can see, these registers don’t store a ton of information. Instead, the bigger pieces of information are stored in random access memory (RAM) or on a hard drive, disk, or some other permanent storage.
Since going out to memory is so “expensive” in terms of how much time it takes to move electrons there, the CPU has several layers of smaller, but faster pieces of memory called cache. These pieces of memory mimic RAM. So, when the CPU wants to read or write to RAM, it first consults the faster cache to see if the address is in there. If it is, then the CPU is done, and a much smaller memory penalty is applied. This is called a cache hit. Otherwise, if the value isn’t in cache, it goes out to RAM (or another bigger, but slower level of cache) to fetch the value, and it incurs a much larger penalty. This is called a cache miss. We will discuss cache later in this course.
Conclusion
As you can see from the concepts we covered above, computer architects have improved computing to a point where we are running into physical limitations, including the distance between components in the CPU. Architects are now forced to look at other ways to improve the performance of these computers, to include parallelism, pipelining, memory hierarchies, and speculation. However, there are still several places to explore.
Some architects have looked at the architecture itself to see if there are ways to improve it. For example, here at the EECS department at UT, the Neuromorphic Group, headed by Drs. Plank, Rose, and Schuman, is designing a whole new approach to CPUs, including artificial intelligence and artificial neural networks.
There is still a lot of growth to be had in the future of computing!
| No previous chapter | Table of Contents | Binary Numbers |