Learning Objectives
- Understand why cache is used and how it improves performance.
- Understand the principles of spatial and temporal locality.
- Differentiate among direct-mapped, set-associative, and fully-associative cache.
- Understand how multilevel cache works.
- Understand the different types of cache misses–“the three Cs”.
- Differentiate between write-through and write-back cache policies.
Cache in General
Cache is a term used to refer to a piece of memory between the CPU’s registers and main memory (RAM). When the memory controller goes out to RAM, it first consults cache. Cache is essentially a subset of the data used in RAM that is used more often. So, instead of taking the performance hit going out to RAM every time, it reads and writes into a smaller piece of memory called cache.
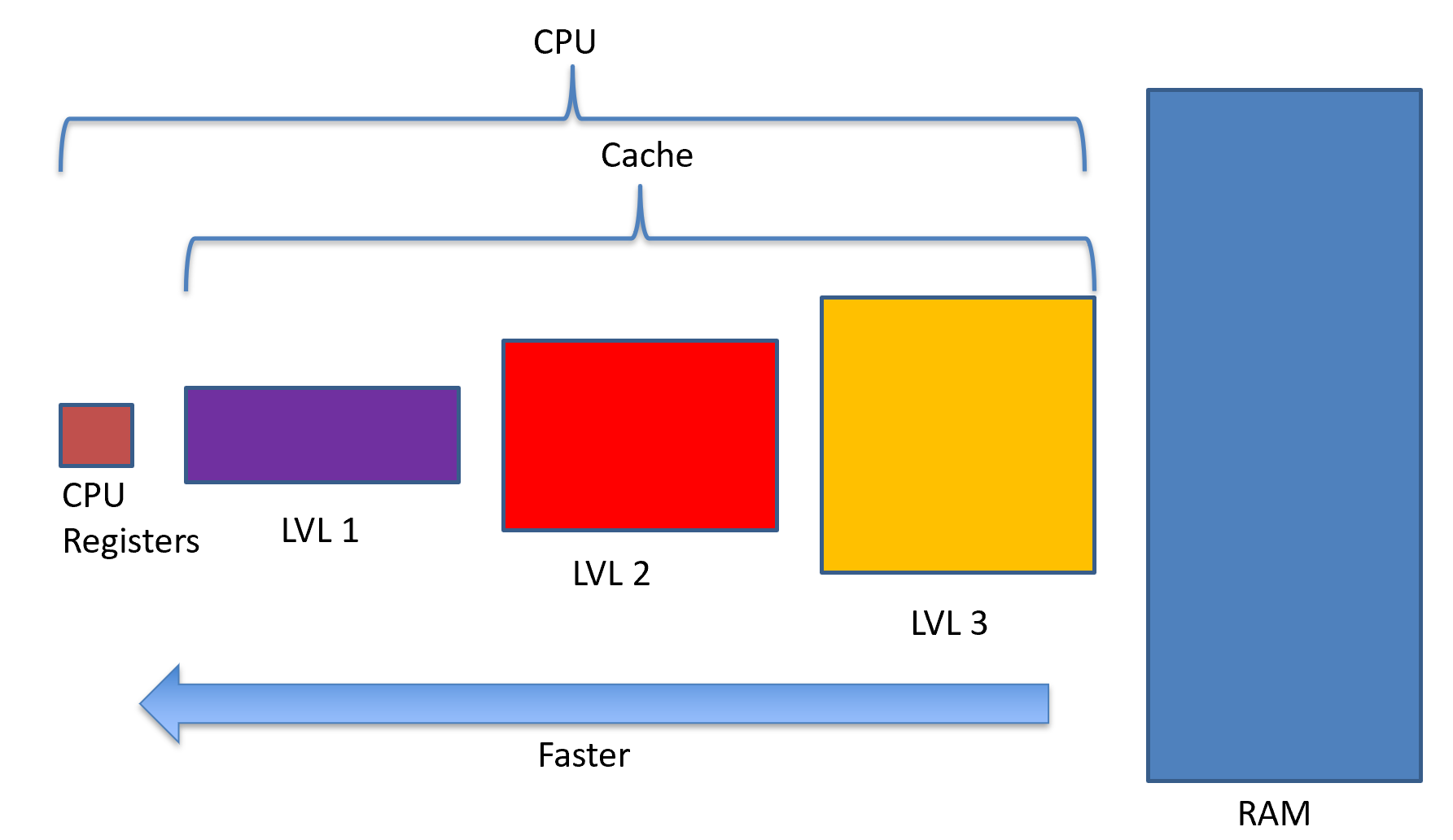
This is the basic building block of multilevel cache. In this case, level 1 is the fastest, but the smallest memory before we get to the CPU registers. Cache is interesting because everything in level 3 cache is also in RAM. Everything in level 2 cache is also in level 3 and in RAM. Everything in level 1 cache is also in level 2 and level 3 and in RAM.
When the CPU asks for memory to load or store, the memory controller starts with level 1 cache. It finds what is known as a tag, which is a portion of the memory address used to find it in a table. The other part of the memory address can be found by the set function itself. The tag and the set will be used to form a full memory address.
If the tag is found, then the memory controller grabs the value from level 1 cache, and its job is done. This is called a cache hit. If the address is not found in level 1 cache, the memory controller then heads off to level 2 cache and looks in there. When the memory controller turns up empty, it is called a cache miss. Obviously, we want to maximize cache hits and minimize cache misses.
Some architectures only have one level of cache, or maybe only two. Some have more than three. For this lecture, I’ll stick with three.
So, now we know how the memory controller treats cache, but how does the cache itself work? There are three types of caches: (1) direct-mapped, (2) set-associative, and (3) fully-associative. Each has a benefit and a drawback.
Temporal and Spatial Locality
Cache operates by storing memory addresses and their values that were accessed most recently. Cache also stores a block of data, which can be upwards of 16 bytes or more depending on the cache design. This means that not only do I get the value I wanted, but I get all the values around that.
Storing the most recent values in cache exploits the principle of temporal locality. The chances that you’ll use a value you previously used is high, so therefore we put it in faster memory.
int main() {
int i;
cout << "Enter a value: ";
cin >> i;
i = i * 2 + 150;
cout << "Modified value is " << i << '\n';
return 0;
}
In COSC102, and some labs here, you’ve seen code like the one above. Notice that we declare i, then input something into it, then manipulate it, then output it. This is temporal locality. Since we declared i, cache is guessing that we’re going to use it sometime soon.
When cache stores values around the one you wanted, it is exploiting the principle of spatial locality. The chances you use a value around the one you just accessed is higher.
int main() {
int age;
int height;
int weight;
cout << "Enter your age, height, and weight: ";
cin >> age >> height >> weight;
int result = age * 150 + height * weight / 30;
cout << "Your XXYYZZ medical result is " << result << '\n';
return 0;
}
Since cache loads in blocks (usually in blocks of 16 bytes), one cache line stores age, height, and weight, which together are 12 bytes. This is an example of spatial locality (as well as temporal locality). When we use age, the chances that we’re going to use height and weight are good too. Since caching uses blocks, height and weight are automatically pulled into cache when we use age.
Direct-mapped Cache
Direct-mapped cache uses a set-function. This function takes a portion of the memory address to locate it inside of the cache. Obviously, since cache is smaller than RAM, more than one memory address will refer to the same set. This is called a collision. In direct-mapped cache, only one memory address can be in a set at one time. The number of sets is determined by the cache designer, and the set function is based on the number of sets.
The following diagram shows how direct-mapped cache works. It has four sets (labeled 0 through 3), so let’s say our set function is \(S(\text{addr})=\text{addr}\land 3\). Recall that 3 is \(11_2\), so with this set function, we can have the possibilities of 0b00, 0b01, 0b10, and 0b11, which equates to set 0, 1, 2, and 3.
The diagram below shows the following addresses entering cache:
0x0 (0 & 3 = 0)
0x4 (4 & 3 = 0)
0x8 (8 & 3 = 0)
Notice that each value goes into set 0.
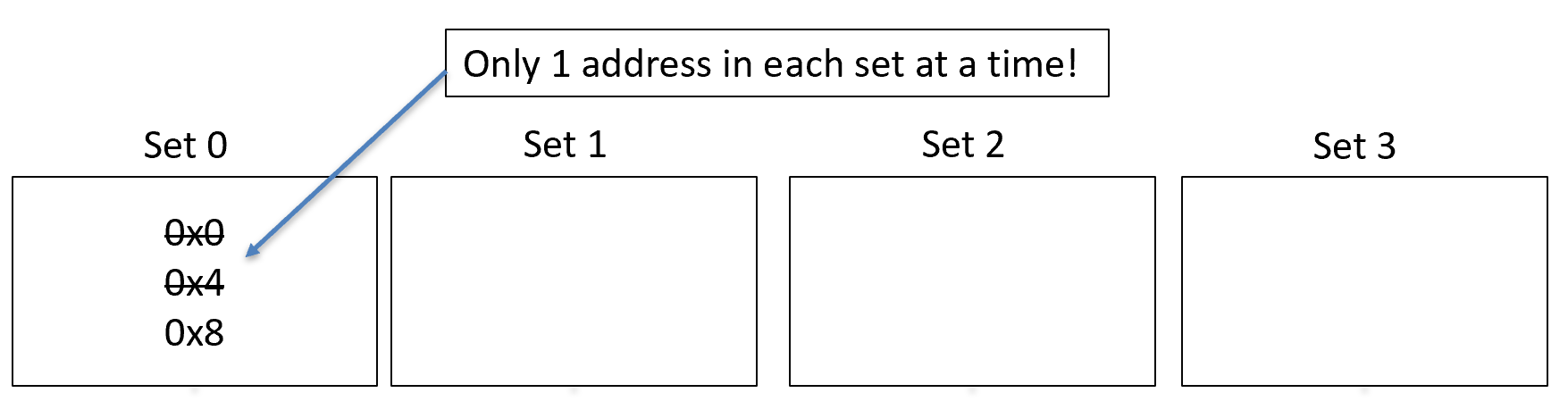
Locating an entry in direct-mapped cache is very simple, which is the benefit of direct-mapped cache. However, look at our cache above. We read three addresses, but they all went into set 0. Sets 1, 2, and 3 were never used, so we just wasted our time. Also recall that in direct-mapped cache, only one value may enter the set. So, when 0x4 came in, it had to kick out 0x0. This is called evicting the previous address.
Direct-mapped cache is considered an n-sets, 1-way cache, where n is the number of sets. Recall that the number of sets is determined by the cache designer. The more sets we have, the larger our cache must be, however the less likely we will have a collision.
Fully-associative Cache
You see how we wasted the other sets in direct-mapped cache. Instead of using sets, we can use all of the cache to store whomever gets into cache first. That is, we essentially have one set. All addresses map to this set, but we divide that set into several ways. The number of ways is the number of memory values we can store in that single set.
For the example above, we could easily store 0x0, 0x4, and 0x8 all in cache. However, since we no longer have a set function, we have to add logic to search the cache for a given memory address. This search takes time, and isn’t free!
Fully-associative cache is said to have 1-set, m-ways.
What happens when we’ve exhausted the number of ways that we have? In this case, we must employ an eviction policy. Below are several eviction policies, but it isn’t an exhaustive list.
Eviction Policies
We need to determine who gets kicked out of cache when we’ve exhausted the number of ways. The policies here are (1) FIFO, (2) LRU, (3) LFU, and (4) random.
First-In, First-Out (FIFO) Eviction Policy
The FIFO eviction policy prioritizes incoming addresses over those that have been in cache already. This takes nothing into account, including the number of times we’ve accessed that memory address, or how recent we’ve used that memory address. So, this isn’t the best policy since we could potentially evict a memory address still being used.
Least Recently Used (LRU) Eviction Policy
The LRU eviction policy keeps track of the last time a memory address was used. When we consider which address to evict, whichever address has the earliest (least recent) usage time gets evicted. This is a big step above FIFO, but it requires us to dedicate cache storage to storing the recency (time).
Least Frequently Used (LFU) Eviction Policy
This is much like the LRU eviction policy, except instead of storing time, we store the number of times we’ve read or written this memory address. When we consider an address to evict, we take the one whose access counter is the smallest (least frequent).
Random
One last policy is just to pick one at random and get rid of it. Amazingly, this actually has a pretty good record of being both efficient and accurate. At the graduate level, you may learn about random algorithms that shockingly are pretty good!
Set-associative Cache
We wasted unused sets with the direct-mapped cache, and we were forced to evict the old addresses. With fully-associative cache, we spent too much time searching for addresses. However, we can compromise by using some of the cache’s memory capacity to form ways. However, since we still have sets, like direct-mapped cache, we can reduce our workload by first locating our set. Then we only search through a fraction of the addresses that we otherwise would have to search in fully-associative cache.
What’s the other issue with set-associative cache? Well, our set function in direct-mapped cache got us one result–the only address in cache. However, with set-associative, our set function gives us several results–all of the addresses in each way. So, we must add logic components to search through cache and find our address. This searching isn’t cost-free, and it takes time.
If we had a 4-set, 4-way set-associative cache, the addresses 0x0, 0x4, 0x8 from the example above would still go into set 0. However, all of the values can be held with one to spare!
When all four ways are taken up by addresses and a fifth comes in, we must determine who gets evicted. Recall that there are several eviction policies that we can employ. Just like fully-associative cache, we are required to evict if one of our sets gets full.
Three-Cs of Cache Misses
There are three ways to get a miss: (1) compulsory, (2) capacity, and (3) conflict.
Compulsory Misses
When we first turn on the computer, there is nothing in cache, so at this point every memory access will be a cache miss. This event is known as a compulsory cache miss.
Capacity Misses
This occurs in set-associative and fully-associative cache. Whenever there is no more space in cache, some address must be evicted and the new one enters. Whenever we go for that old address that was just evicted, we call this a capacity cache miss.
Conflict Misses
Conflict misses occur in set-associative and direct-mapped cache. Whenever we have two addresses that map to the same set, something has to be evicted. This is called a conflict cache miss.
Write Policies
Whenever we write a value, we have a choice to make. (1) Do we write just to cache? Besides, it’s just as good as memory, or (2) do we write all the way back to RAM and every other cache level in between.
The write-through write policy will write all the way through to RAM for every write. Therefore, writes incur a penalty from all cache levels as well as RAM.
The write-back write policy will write only to cache. However, whenever the memory value is evicted, then its value gets written back to either a higher level cache or to RAM.
The write-through policy incurs the most significant penalty, however it keeps everything nice and synchronized. Recall that we can have multiple functional units executing simultaneously (multiple CPUs or multiple cores). Generally, each core has its own level 1 and level 2 caches. What happens when another core wants to access the same memory address as a different core? In this case, if we have the write-through policy, there is no issue. The backing store (RAM) will be synchronized across all CPUs.
On the other hand, with a write-back policy, we no longer incur a performance penalty for writes. However, now it’s very difficult to keep everything synchronized, so we must be careful when accessing memory by multiple cores. There are techniques to doing this, but we will save that for your upper-level courses.