Contents
Introduction
Programming languages are essential to the life of a computer scientist, even if we aren’t programmers per se, a programming language blends many different computer science disciplines, including psychology, ergonomics, and mathematics.
A programming language is essentially a language with syntax and semantics used to solve computational problems.
History
Languages
All languages, whether textual, aural, or even graphical (such as MIT’s AppInventor), have a syntax and semantic rules. The syntax of a language means the rules that define the structure for something to be valid. For example, the English sentence “The C Programming Language over 50 years old.” is missing a verb, which gives action to the subject acting upon the object. Therefore, this sentence is not syntactically valid for well established English.
When we look at a programming language, such as C, we know there is a way do do things. For example,
int i = 10;
The syntax here is <type> <name> <operator> <initialization value> ;. So, all statements in the C/C++ language must terminate with a semicolon. If I leave off the semicolon, then the language’s syntax is violated, and the compiler will not be able to compile the code.
The semantics of a language gives the meaning behind the statements in a program. Taking the example above, the syntax just states the order and types of words or symbols in there. However, the semantics of this statement is “declare a 4-byte value that stores whole numbers called i and set it equal to the initial value of 10.” In C++, this will filter down into a set of CPU instructions to accomplish this statement. First, the stack is moved to make room for four bytes. Then, those four bytes are set to 10. Finally, C++ now knows that when we refer to i that it means the memory address when we moved the stack.
For computers, our languages can be split into two general categories: general purpose and domain specific. The split is not the cleanest, but there is a general thread that separates the two types of languages.
General Purpose Languages (GPL)
A general purpose language is a language that eventually devolves into some computational instructions, whether this be for a central processing unit (CPU) or any other type of computational device. A general purpose language is primarily used to implement computations.
High Level Programming Languages
A high level language abstracts the system in some way away from the program itself. For example, when we declare “int i” in C, we don’t really care where it is or how it does it. We just know we want something that stores whole numbers that we call i.
Low Level Programming Languages
A low level programming language is typically specific to a particular machine. A good example of this is the assembly programming language. There is little abstraction, and really the only good use of assembly is to make it so that a human could quickly write instructions that normally would have to be converted first into 0s and 1s.
Standard Library
Many programming languages come with a standard library. This is a set of routines (aka the runtime) and constants that must be included into the language for one to say they’ve implemented the given language. For example, the C programming language has the C standard library. We can turn off the standard library, but in come language, such as C++, this means that language features, such as initializer lists, dynamic casting, exceptions, and so forth will also be turned off.
Domain Specific Languages (DSL)
A domain specific language is a language specific to some domain. For example, the Hypertext Markup Language (HTML) is specific to the hypertext domain. We typically won’t use HTML to solve computational problem (notwithstanding embedding Javascript).
There are several other examples of a domain specific language:
- SQL – Structured Query Language – used for databases.
- GLSL/HLSL – GPU Shader Languages – used for writing programs embedded in the GPU pipeline.
- VHDL – Very High-Level Descriptor Language – used for describing logic and circuits in a textual way.
- UML – Unified Modeling Language – used to convey visually the design of a system.
As you can see above, some languages, such as UML, aren’t even specific to a computer. Traditionally, one would use UML to outline a system, which can then be more specifically implemented some other way, to include using a general purpose programming language, such as C or C++.
Language Styles
Not all languages use the same style. We are used to the imperative programming style, which is used in C, C++, and Java. However, there are other styles, such as functional programming, which is composed of and applies mathematical functions for computation.
Compilers
A compiler is a tool that converts a higher-level language into a lower-level language. For example, the C compiler transforms C source code into assembly source code. The term compiler may take on different meanings depending on who you ask because of how we interact with it. For example, if I type “gcc -o hello world.c”, then the C code turns into an executable called “hello”. However, this is hiding many, many stages that convert the high-level C source code into executable machine code.
Lexical Analysis
The first stage is lexical analysis. In languages (not specifically programming languages), lexical analysis transforms text into meaningful groups. For example, in English, we would lexically analyze sentences to form groups of nouns, verbs, adjectives, and so forth. In programming languages, instead of nouns verbs, and so forth, we could group them into comments, keywords, separators/punctuation, operators, literals, and identifiers.
A lexical analyzer runs the source code through a group of rules called grammar to determine which category the text enters. This can be done based on symbols, names, or the order in which the lexical analyzer finds the values.
A common lexical analyzer generator (you give it grammar, it gives you a lexer) is called flex, and is commonly included in the suite of GNU tools. In fact, flex is available on all of the Hydra/Tesla machines.
~> flex --help Usage: flex [OPTIONS] [FILE]... Generates programs that perform pattern-matching on text.
Parsing
The output of a lexical analyzer is fed into a parser. The parser now looks for each of these groups and applies them to form the semantic order. A common way to represent the order of the semantics is the abstract syntax tree (AST).
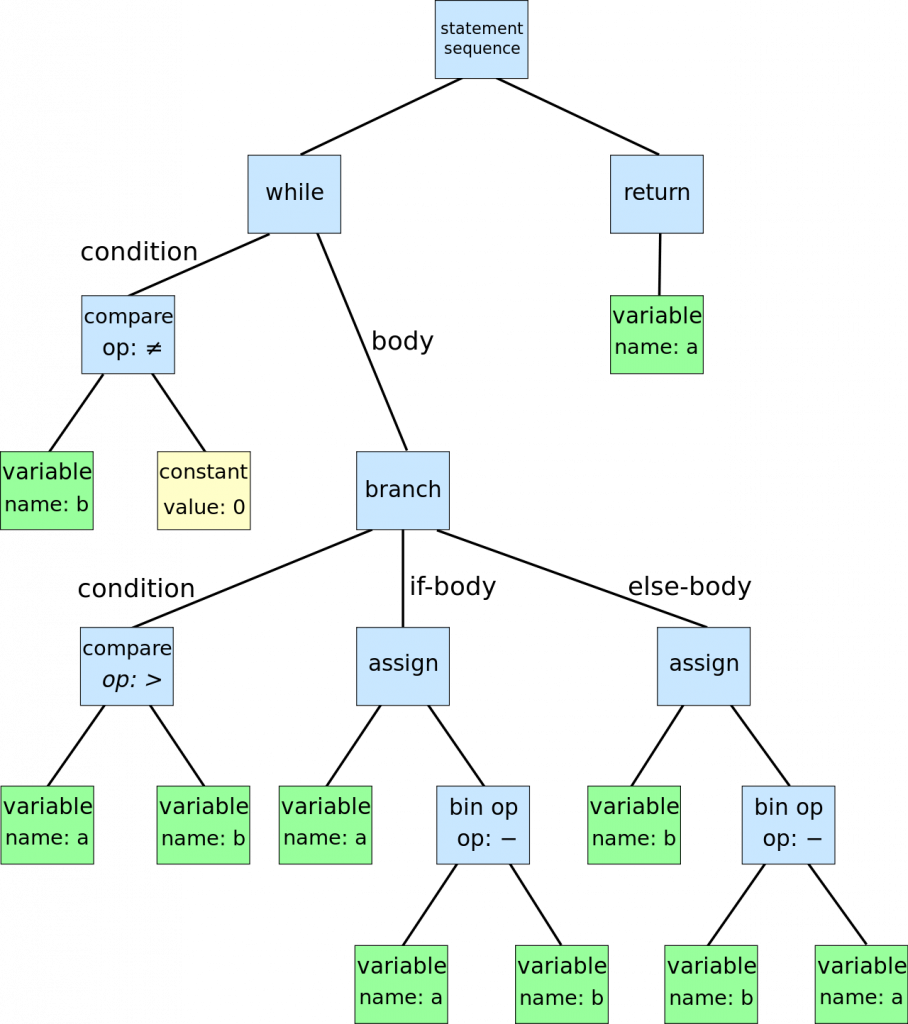
By following the tree above, we can apply the operands to an operation.
Semantic Analysis
After we generate the tree, we need to apply what the tree is going to do. This is called semantic analysis. This puts meaning to the operators, such as the boxes with assign, bin op, and branch above.
Intermediate Representation Generation
For many languages, an intermediate representation (IR) is generated mainly to debug certain aspects of the language or to tweak the output of the lexer, parser, or semantic analyzer. It is rarely kept around for programmers, but more and more, several programming languages, such as Java and C#, use an intermediate representation (bytecode in Java, Microsoft Intermediate Language [MSIL] in C#), which is further processed into machine code via a virtual machine. For Java, that’s called the Java Virtual Machine (JVM) and for C# it’s called .NET.
Optimization
There are several things we can do to optimize the output of a language. For example,
for (int i = 0;i < 10;i++);
In the code above, we have a branch instruction for the condition i < 10. However, if we can detect that this loop will always run 10 times, we can unroll the loop and avoid any branch instructions at all, and hence, never incur a branch prediction penalty. This is one of many, many optimizations we can perform on the code to make it smaller or run faster. For gcc and g++, we can control the optimizations that are performed by using the -O? switch. For example, -O2 is the “second level optimization” and -Os “optimizes for size”. You can see the optimizations performed at each level here: https://gcc.gnu.org/onlinedocs/gcc/Optimize-Options.html
Machine Code Generation
The last stage is to generate the machine code. This can be done ahead of time (AOT), where the machine code is stored before it is executed, or it can be done just in time (JIT) where the machine code is generated while the program is executing.
Ahead of time compilation is what most of us our used to when we write C and C++ programs. The native machine code is stored in an executable. When we “execute” it, the machine code is directly loaded into RAM and ran on the computer. This is why we can’t copy an executable from one architecture to another and expect it to run.
Just in time compilation usually compiles down to an intermediate representation. Then, this IR is further interpreted by a virtual machine to run instructions at run-time, or while the virtual machine is running.
Typing Systems
Typing systems are basically how we look at data within a programming language. This allows a programming language to assign memory, check consistency, and apply context to operators. Programming languages each have a typing system that falls within one of four quadrants: strong/dynamic, strong/static, weak/dynamic, and weak/static (see figure below).
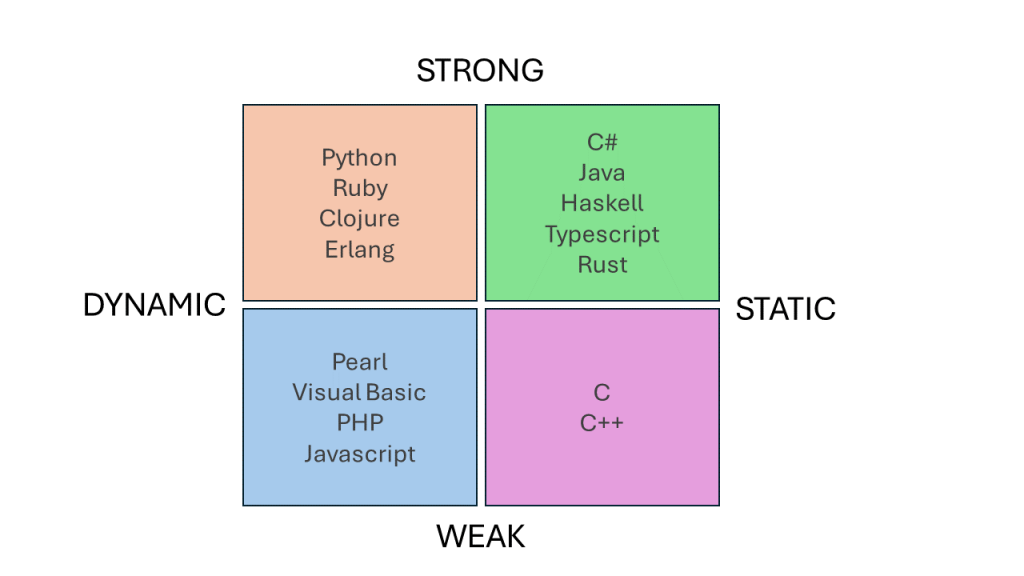
Strong vs. Weak
A strong type system requires explicit conversions or denotations of data types, whereas a weak type system will either automatically convert types for you. We can see this with Java vs. C:
// C will auto-convert 77.3 into an integer, and i will get the value 77 int i = 77.3; // Java will auto-widen, but not auto-narrow. Narrowing requires an explicit cast. // The following is an error in Java. int i = 77.3;
Static vs. Dynamic
A static type system checks all types and conversions at compile time. This means that all typing-related choices (e.g., instruction choice, width choices, and memory sizes) are already known. The opposite is a dynamic type system, where the type is not evaluated or known until run-time. This means that an invalid type or conversion may never be known until the execution path attempts to convert it. This is one of my main problems with Python.
Aggregation
Aggregation refers to lumping more than one piece of data within the same data type. You’ve seen several examples of this already in two ways: (1) arrays and (2) structures. However, if we want to be able to convert between data types by name, we can use a union, which is available in Rust, C, and C++. C# allows you to fake a union, but it is not intrinsic to the language.
A union has several members, but all members use the same memory. In other words, they overlap memory regions. Therefore, a union’s size is the largest member in the union. Below is an example of a union in C++ that takes 8 bytes.
union MyUnion {
int a;
double b;
};
Unions are not structures in that we can distinctly store both “int a” and “double b” above. Instead, “int a” occupies the first four bytes of double b. So, if I changed the value of a, I’m changing the value of the upper four bytes of b. This can lead to some unpredictable and perhaps funny results.
int main() {
MyUnion mu;
mu.b = 14.5;
mu.a = 33;
cout << mu.b << '\n';
}
So why ever use a union? The main reason is to save bytes if we need to store an either an integer or a double, but not both at the same time. If I had to store both, it would require at least 12 bytes, but with padding rules, maybe 16 bytes!